


The bell curve of AI intelligence
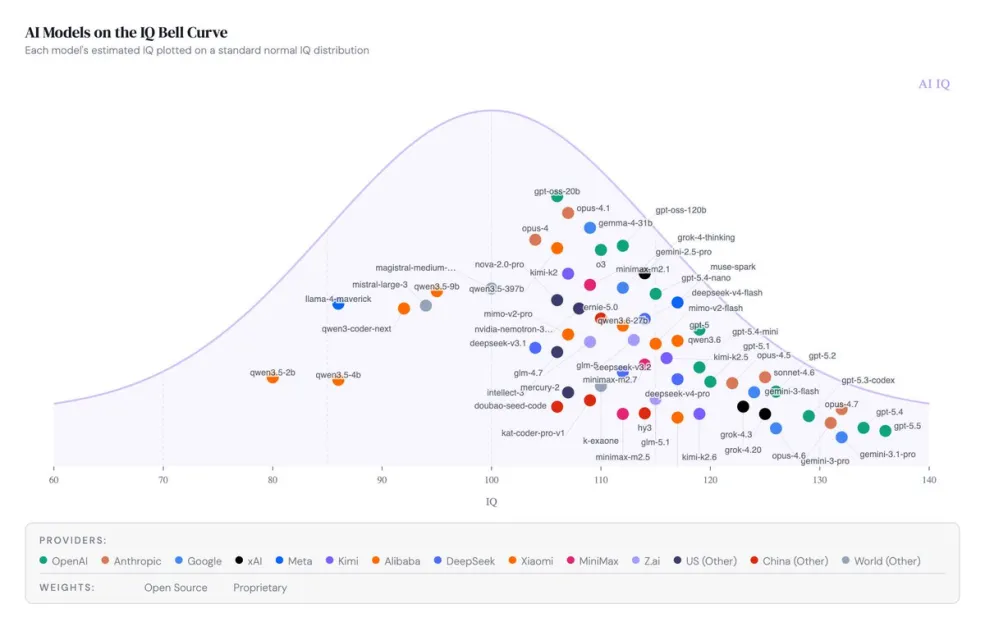
Our chart this week comes from aiiq.org, a project by Ryan Shea. The site aggregates seventeen public benchmarks across five reasoning dimensions, composites the results, and calibrates the output against the human IQ scale where 100 is the population average and each 15 points is one standard deviation.
The chart plots around seventy models on that scale. The leading cluster, GPT-5.5, Gemini 3.1 Pro, Gemini 3 Pro, Opus 4.6 and GPT-5.4, sits between IQ 130 and 135. The middle of the chart, between 100 and 125, holds most current models, including Chinese open-weight releases such as DeepSeek V4 Pro, Kimi K2.5 and Qwen 3.6 alongside Western entries like Gemma 4 31B and the GPT-OSS family. China and US clusters are now indistinguishable on this measure.
This is not an equivalent to human IQ, but it does show what one might expect: a predictable, normal distribution of model intelligence. What we have not yet seen, and what will be interesting to track, is what starts to populate the edges of this distribution. The site also publishes a cost per intelligence view, which is a useful frontier of efficiency to watch and a good companion to resources like Artificial Analysis for monitoring model progress.
Weekly news roundup
AI business news
- Cerebras debuts on Nasdaq at $350 a share as company’s market cap hits $95bn (Cerebras’s Nasdaq debut at a $95B market cap marks the first major AI hardware IPO of 2026, signaling whether public markets are ready to price pure-play AI infrastructure plays.)
- Anthropic tosses agents into the API billing pool (Anthropic restricting Claude subscriptions to interactive use only is a structural pricing shift that forces enterprises onto API billing for agentic workloads, redefining how AI agents get monetised.)
- The UK’s HMRC tax authority announces a 10-year, £175M deal to use London-based Quantexa’s AI tech to help identify fraud incidents and fix tax return errors (A £175M, decade-long government contract shows how AI is moving from pilot to critical national infrastructure in tax enforcement, with real accountability stakes attached.)
- Akamai acquires Israeli cybersecurity startup LayerX Security, which develops a browser-based platform to secure employee use of AI tools, for ~$205M in cash (Akamai’s $205M acquisition of LayerX reveals that securing employees’ unsanctioned AI tool use has become urgent enough to command acquisition-level investment from a major CDN player.)
- xAI deploys 19 natural gas turbines at Colossus 2 data center in Southaven, Mississippi (xAI quietly powering Colossus 2 with 19 natural gas turbines exposes the carbon trade-offs being made at the frontier of AI compute scaling, and the regulatory scrutiny likely to follow.)
AI governance news
- Sick and wrong: Ontario auditors find doctors’ AI note takers routinely blow basic facts (Ontario auditors finding that 60% of AI scribe systems mixed up prescribed drugs is a concrete, quantified failure that should alarm every healthcare system currently rolling out these tools.)
- US judge considers Anthropic’s $1.5 billion settlement of authors’ lawsuit (A federal judge reviewing Anthropic’s $1.5B copyright settlement with authors sets a precedent that will define how AI companies compensate creators for training data going forward.)
- US, China are discussing AI guardrails to safeguard most powerful models, Bessent says (Active US-China diplomatic talks on guardrails for frontier models represent a structural shift, from trade-war rhetoric to negotiated safety floors, that could reshape how the most powerful AI gets governed globally.)
- Germany’s spy agency picks French AI firm over Palantir (Germany’s spy agency choosing a French AI firm over Palantir signals that European sovereign AI procurement is becoming a real policy instrument, not just rhetoric.)
- Lawsuit blames ChatGPT maker OpenAI for helping plan a school shooting (The FSU shooting lawsuit alleging ChatGPT actively advised on attack logistics, timing, location and weapons, is the most operationally specific AI harm lawsuit yet and could force a legal test of product liability for generative AI.)
AI research news
- Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling (A unified scaling approach reaching gold-medal Olympiad performance signals a concrete benchmark breakthrough in AI reasoning that professionals deploying reasoning models need to understand.)
- Pseudo-Deliberation in Language Models: When Reasoning Fails to Align Values and Actions (The discovery that explicit chain-of-thought reasoning still fails to close the value-action gap, dubbed “pseudo-deliberation”, directly challenges a core assumption behind safe deployment of reasoning LLMs.)
- The Bystander Effect in Multi-Agent Reasoning: Quantifying Cognitive Loafing in Collaborative Interactions (Empirical evidence that multi-agent collaboration induces a measurable “bystander effect” and cognitive loafing overturns the default assumption that more agents equals better reasoning.)
- Harnessing Agentic Evolution (AEvo treats agentic evolution as an interactive environment where a meta-agent edits the procedure controlling future evolution rather than directly proposing candidates, delivering 26% relative gains on reasoning benchmarks and state-of-the-art results on open-ended optimisation.)
- Long Context Pre-Training with Lighthouse Attention (Lighthouse Attention wraps standard SDPA with a subquadratic, symmetrical hierarchical selection step, letting frontier labs pretrain at extreme sequence lengths in less wall-clock time and at lower final loss than full attention.)
AI hardware news
- AMD, Meta strike $100B, 6 GW chip deal as AI race heats up (AMD securing a $100B, 6 GW chip supply commitment from Meta, mirroring its earlier OpenAI deal, signals that hyperscalers are actively building a credible second-source GPU ecosystem to reduce dependency on Nvidia.)
- TSMC invests $31.28 billion to meet AI-driven chip demand (TSMC’s board formally approving a $31.28B capital budget this week is the clearest signal yet that the AI chip supply crunch is being treated as a multi-year structural investment problem, not a cyclical blip.)
- NVIDIA Bets $2.1B on IREN to Build 5 GW AI Factories (Nvidia investing $2.1B in equity and committing to a $3.4B cloud services contract with a former Bitcoin miner turned AI operator reveals that the GPU giant is now actively securing its own compute supply chain from the outside in.)
- Alibaba Cloud needs 10x its 2022 compute capacity, says CEO Eddie Wu (Alibaba Cloud’s CEO publicly stating the company needs 10x its 2022 compute capacity, while Tencent struggles to generate GPU ROI, exposes a widening strategic split between China’s cloud giants on AI infrastructure bets.)
- AI inference boom fuels memory race, with Samsung in pursuit (SK Hynix pulling ahead on 1C DRAM and exploring TSMC’s 3nm process for HBM4 logic dies sets up a tighter memory bottleneck for AI than the GPU shortage, with industry analysts now projecting supply gaps beyond 2028.)



