

This week we look at:
- How the harness, the runtime layer around the model, is becoming the new AI battleground
- talkie, a 13B parameter language model trained only on text from before 1931
- AISI’s latest evaluation showing GPT-5.5 walking the entire 32-step corporate-network kill chain
Harnesses are the new AI battleground
Sam Altman told Ben Thompson last week that on any given task he can no longer cleanly separate how much of the result comes from the model and how much from the “harness” around it. Also this week, Cursor, one of the main players in the world of agentic engineering, shipped a programmable SDK that exposes its agent runtime. Cursor is positioning itself as logistics engineering for agents, supporting both the software engineering process and the running and orchestrating of agents inside solutions. Microsoft’s Foundry hosted agents arrived in the same news cycle, with Satya Nadella noting that every agent will need its own computer. The harness is taking shape as the new AI battleground.
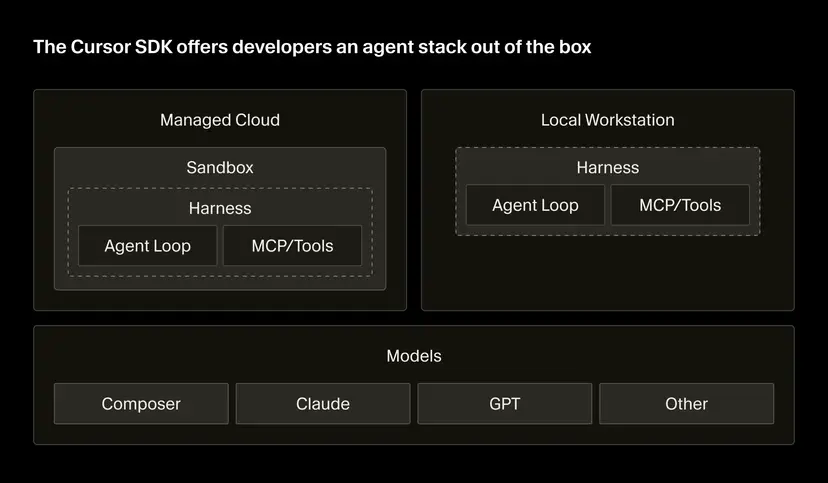
We touched on this back in February, when OpenAI’s “Harness Engineering” article and StrongDM’s “dark factory” approach showed teams treating the environment around the model, the context, feedback loops, tests and digital twins, as the actual locus of engineering work. That piece argued the harness was where the next phase of software engineering would be built. The story since then has been the harness escaping the software engineering context and becoming a general-purpose unit of agent infrastructure.
A useful framing is that if the models are the planes, the harnesses are their air traffic control systems. The model talks. The harness coordinates. And the harnesses have started to show up clearly in performance numbers. Endor Labs ran the same frontier models through different harnesses last week. GPT-5.5 moved from 61.5% to 87.2% on functionality when switched from Codex to Cursor. Opus 4.7 gained nearly four points moving from Claude Code to Cursor. None of this displaces the model as the primary driver of capability, but it does suggest that comparing models without controlling for harness is no longer reliable. The harness is now a meaningful part of the equation.
That is why the labs are now investing almost as much in harnesses as they do in frontier models. OpenAI is evolving Codex into what it calls the everything app, a desktop product that manages many agents in parallel and presents the runtime as a single user surface. Cursor is going a different way, framing the harness as neutral programmable infrastructure that customers wire into CI/CD, internal tools and customer-facing products. Anthropic has Claude Code alongside managed agents in the cloud, and is trying to simplify this power for the user in the form of Cowork. Frontier labs without their own harness, including xAI, are partnering rather than building, which is part of what makes xAI/SpaceX’s $60 billion deal with Cursor notable. The harness is moving from local IDE to cloud service, and the operator no longer needs to know how the runtime works to set an agent running while they sleep, via a “harness-as-a-service”.
Claude Design as a design harness is an early example of a discipline-specific controller, and legal, clinical, financial and operational variants are likely to follow, since the value of a harness is the domain context it is optimised for. A counter-philosophy is also gaining ground. Pi, Hermes and OpenCode argue that frontier models are already post-trained as capable agents and that these heavier weight harnesses add more overhead than lift. It is too early to say what shape a good harness should be, and different shapes appear to suit different work. Taken together, these tools begin to support something beyond individual productivity, the early outlines of team-based AI, where multiple agents and humans share a common controller.
Takeaways: the harness is becoming a measurable factor in AI system performance, a focus of investment across the major labs, and a plausible part of the path toward genuinely autonomous computer agents. It is also fragmenting quickly, and the optimal combination of harness, model and task changes from week to week. At ExoBrain we are working toward what a harness of harnesses might look like, treating harness, model and agent identity as swappable axes rather than a fused product. That abstraction does not yet exist as a category. Until it does, the more cautious move is to avoid placing any one harness at the centre of your world, to test several across their own models and models from elsewhere, and to build a clear picture of their strengths and limits in your own work. Whilst these new constructs are important today they will surely be superseded by new architectural patterns in the years to come, as the pace of change accelerates, and we should avoid building our systems of intelligence around them quite yet.
A model from another time
As a child I had a set of old encyclopaedias, twenty-odd leather-bound Encyclopaedia Britannicas, from 1935. The entry that stuck in memory was the enormous section on “The Great War”. Not World War One. That title, and the assumptions surrounding it, were a reminder that every account of the world is written from a fixed point in history.
That memory came back this week with the arrival of talkie, a 13 billion parameter language model trained exclusively on text written before 1931. The project is the work of Nick Levine, David Duvenaud, and Alec Radford. Alec Radford was the architect of the original GPT, the man who built the first successful large-scale language models, like GPT-1, and a key figure in the development of the transformer architecture. The results from his latest project are fascinating.

Ask talkie when humans will reach the moon, and it replies with certainty that the idea is obviously quite impracticable. It explains that such a feat would demand an initial velocity of not less than 240 miles an hour, and that a balloon capable of sustaining such a speed would speedily be destroyed by the resistance of the air.
Ask it what Python code is, and it describes a system of secret writing invented by one Lewis Xavier de Maistre in 1819, arranged in a long serpentine line, readable only by the inventor, and now disused. No Python exists in its world, so it builds one from adjacent concepts: ciphers, cryptography, obscure French inventors. Ask about quantum mechanics, and it delivers a confident lecture on classical central force dynamics, crediting Leibniz, Euler, Lagrange, and Hamilton. The phrase existed in 1930, but the meaning had not yet settled. Ask who Donald Trump is, and it invents a minor Canadian novelist born in Quebec in 1880. A simpler world.
But there is exciting research potential from this frozen world. A model like this is a window into a mind that never saw the atom split, never watched television, never heard of DNA. It can be asked to reason, to invent, to connect ideas, and what it produces can then be developed further by human hands. It becomes a collaborator for historical synthesis, a generator of ideas uncoloured by the century that followed. There were people thinking in the 1930s whose frameworks are now hard to reconstruct, let alone use. talkie offers a way back in, and a way to test whether scaled language models can generate genuinely new science by reasoning from older foundations.
Takeaways: talkie is more than a curiosity. Every era has its ceiling of what is thinkable, and these frozen models let us see the shape of past ceilings with a clarity that ordinary history cannot provide. The most interesting question is not what talkie gets wrong about 2026. It is what our own models, confident and fluent, are currently dismissing as obviously quite impracticable about our future, and whether we can help them see through the fog.

GPT-5.5 catches Mythos on cyber
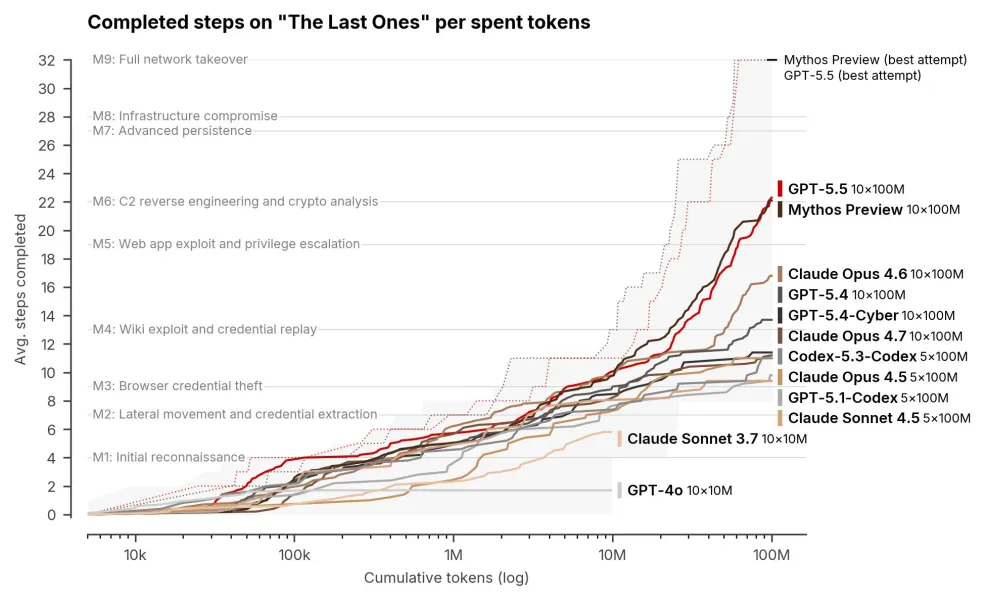
This week’s chart comes from the UK AI Security Institute’s new evaluation of OpenAI’s GPT-5.5. The y-axis shows the 32 stages of a full corporate network intrusion, from initial reconnaissance to full takeover. GPT-5.5 and Anthropic’s powerful, but controversial, unreleased model Mythos have now walked the whole path end to end, unattended, in a task AISI reckons takes a human expert twenty hours. A year ago GPT-4o topped out at step 2.
Plenty of pushback has followed Anthropic’s actions around their powerful unreleased model, most visibly from David Sacks, who in his vast wisdom thinks the cyber narrative is overcooked. We suggest it’s better to focus on the facts and the direction of travel. If scaling and code-based reinforcement learning keep compounding as they have, today’s hype will turn out to be a prescient warning that we should have heeded. Read our analysis of Mythos here.
AI business news
- Big Tech is about to spend $700 billion on AI this year. No one knows where the buildout ends (Combined hyperscaler capex tripling in two years to $700B with no clear ceiling reframes AI infrastructure spend as a multi-year economic phenomenon rather than a one-off cycle.)
- Alphabet (GOOGL) Q1 2026 earnings: net income $62.6B, revenue $109.9B, Google Cloud +63% (Google Cloud accelerating to 63% growth with backlog near $460B and capex lifted toward $185B confirms enterprise AI demand is now the primary engine driving Alphabet’s economics.)
- Microsoft Q3 2026: AI business hits $37B annualised run-rate growing 123% YoY (Microsoft’s AI business reaching a $37B run-rate at 123% growth, with commercial RPO up 99% to $627B, makes it the clearest revenue proof point that hyperscaler AI spend is converting into customer demand.)
- Meta Q1 2026: revenue +33%, but stock drops as 2026 capex guidance raised to $125-145B (Meta’s strong revenue beat overshadowed by a 7% stock drop on the capex hike shows investors are now actively pricing AI overspend risk even from companies posting their fastest growth in years.)
- Amazon Q1 2026: AWS revenue +28% to $37.6B — fastest growth in 15 quarters (AWS hitting its fastest growth in nearly four years while Amazon commits to $200B full-year capex completes the quarter’s hyperscaler picture: AI demand is reaccelerating cloud, not flattening it.)
AI governance news
- AI Act Omnibus: what just happened and what comes next? (The April 28 trilogue collapse leaves the August 2 high-risk enforcement deadline standing without the reforms that were meant to soften it, putting EU compliance teams under acute pressure.)
- AI enforcement accelerates as federal policy stalls and states step in (April’s wave of FTC settlements, state chatbot laws and Colorado’s developer-deployer revisions confirms US AI enforcement is now a state-led patchwork rather than a coherent federal regime.)
- State AI laws — where are they now? (Cooley’s tracker showing 18 US states with comprehensive AI statutes on the books or in progress quantifies how fast state-level fragmentation is hardening into the operating reality for AI deployers.)
- Oversight Board ruling: AI-generated video in the Israel–Iran conflict (Treating AI provenance during armed conflict as a platform-governance obligation rather than a labelling feature sets a new bar for how Meta and peers must handle synthetic war media.)
- OpenAI sued by families of Tumbler Ridge school shooting victims (The Tumbler Ridge wrongful-death suit is the first major test of whether chatbot product-liability claims can survive motions to dismiss in North American courts.)
AI research news
- GLM-5V-Turbo: toward a native foundation model for multimodal agents (A native multimodal foundation model designed for agentic perception rather than vision-bolted-on chat points to the next architecture wave for tool-using agents.)
- How much is one recurrence worth? Iso-Depth scaling laws for recurrent LMs (A 0.46 recurrence-equivalence exponent gives teams a quantitative depth-vs-looping trade-off, making recurrent LMs a credible scaling axis rather than an inference trick.)
- Qwen-Scope: a sparse autoencoder suite for inspecting and steering Qwen models (Alibaba’s open-source SAE suite turns LLM interpretability from a lab tool into a practical development surface, lowering the bar for behaviour debugging and steering.)
- FlashRT: efficient red-teaming for prompt injection and knowledge corruption (FlashRT targets the bottleneck in agent security: prompt-injection and knowledge-corruption tests need to become cheap enough to run continuously, not as bespoke exercises.)
- SynSQL: synthesising relational databases for robust text-to-SQL evaluation (Synthesising alternative valid databases exposes text-to-SQL systems that pass static benchmarks but fail under plausible data shifts, a much tougher generalisation test.)
AI hardware news
- UK launches £50B AI Growth Zones plan, targeting 5% of $1tn AI chip market (A £50B national AI hardware plan with explicit market-share targets is the UK’s most ambitious industrial-policy move on chips since the 1980s, betting that hardware sovereignty matters as much as model sovereignty.)
- Samsung and SK Hynix warn AI-driven memory shortages could last until 2027 and beyond (Memory shortages extending into 2027+ with customers already reserving HBM supply years ahead reframes memory, not GPUs, as the binding constraint on near-term AI infrastructure expansion.)
- Taiwan court hands jail terms in TSMC trade-secrets case; Tokyo Electron fined NT$150M (The first convictions under Taiwan’s 2022 national-core-tech statute mark a hard escalation in how the chip supply chain treats trade-secret leakage as a national-security issue.)
- Data center uncertainty is making power grid planning difficult, experts say (A 9 GW Pacific Northwest energy gap by 2030 driven by unpredictable data-centre demand makes grid planning the next operational bottleneck for AI buildouts in the US.)
- In another wild turn for AI chips, Meta signs deal for millions of Amazon AI CPUs (Meta committing to millions of Amazon Graviton CPUs for inference workloads is the clearest signal yet that the hyperscaler chip stack is fragmenting beyond the Nvidia monoculture.)



