GPT-5.2 and the contours of progress
OpenAI’s GPT-5.2 release highlights a competitive response to rivals with strong benchmark scores, yet developer feedback reveals significant issues with tool chaining, reliability, and creative output.

Joel Miller

OpenAI’s GPT-5.2 is here, and it arrives under unusual circumstances. The company declared “Code Red” in early December after Google’s Gemini 3 landed with record benchmark scores and Anthropic’s Claude Opus 4.5 quickly became the favourite among developers for its reliable tool use and natural coding flow. Sam Altman’s internal memo halted work on ads, shopping tools, and health agents to focus all resources on a competitive response. The result shipped on December 11th, just weeks after 5.1.
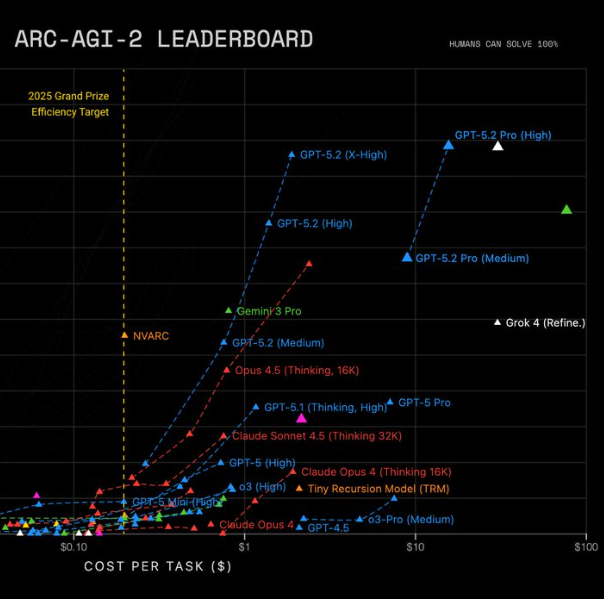
The model brings a 400,000 token context window, a claimed 38% reduction in hallucinations, and three tiers designed for different needs: Instant for speed, Thinking for balanced reasoning, and Pro for deep, expensive cognition. The benchmarks look strong. On ARC-AGI-2, a test of abstract visual reasoning that stumped models just months ago, GPT-5.2 Pro scores 54.2%, clearing Gemini 3’s 31.1% and Opus 4.5’s 37.6% by a wide margin. On the AIME 2025 maths exam, it hits 100% without using tools. Long-context retrieval approaches perfection at 256,000 tokens. OpenAI’s own GDP-val benchmark, which measures performance on professional knowledge work, shows the model outperforming human experts in 70.9% of comparisons across 44 occupations.
The enterprise pitch is apparent. Microsoft’s Satya Nadella calls it a “turning point” for business workflows, and GitHub has rolled it into Copilot. The pricing, up 17% from GPT-5.1 to $1.75 per million input tokens, signals who the intended customer is. This is a model built for companies with budgets.
But the practitioners who have spent the past 48 hours testing GPT-5.2 are telling a more mixed story. “It’s not very good, is it?” is the verdict from one popular AI podcast within hours of release. Developers are finding tool chaining unreliable. The model can call a tool once without issue, but struggles to chain multiple calls together or recover gracefully from errors. Anthropic’s models, by contrast, seem to have an internal clock, pacing themselves, checking their work, and asking for another pass when needed. GPT-5.2 tries to do everything in one aggressive shot, and when it fails, it just fails. SimpleBench, which tests common-sense spatio-temporal reasoning, shows GPT-5.2 and GPT-5.2 Pro both scoring worse than their GPT-5 counterparts.
Creative users are finding it “soulless.” One tester calls it a “glorified calculator” for novelists. Writing engagement scores trail Anthropic’s Sonnet 4.5 by six points. The safety tuning feels heavy-handed to many, with a general reluctance to commit that degrades capability scores in measurable ways. The model appears to have knowledge it will not use.
Speed remains problematic for the Pro tier. Matt Shumer, an early tester with access to the model before launch, reports that it can “think for a long time and still make a big mistake, wasting a lot of my time.” Theo, a coding-focused YouTuber, describes 30 to 50 minute waits for complex tasks. The ARC Prize team cannot even verify GPT-5.2 Pro’s extra-high reasoning mode on ARC-AGI-2 because the API keeps timing out.
Yet others are genuinely impressed with what they are seeing. For deep research, for complex multi-step reasoning, for processing vast documents, the model delivers capabilities that were not available at any price a year ago. Shumer calls it “the best model in the world” for tasks no other model can touch. Enterprise evaluations in finance and life sciences show meaningful reasoning improvements over previous generations. And the ARC-AGI efficiency gains are remarkable: a year ago, a special preview of OpenAI’s o3 scored 88% on ARC-AGI-1 at $4,500 per task. GPT-5.2 Pro now hits 90.5% at just $11.64, representing a 390x efficiency improvement in twelve months.
So which is it? Best model ever, or rushed disappointment? The answer is both, and this is what matters most about GPT-5.2.
We are reaching the end of 2025 with four big frontier models, Gemini 3 Pro, Claude Opus 4.5, Grok 4.1, and GPT-5.2, that are all genuinely strong. Scaling has not hit any hard wall. Test-time compute, where models spend more inference cycles “thinking” before responding, continues to extend capability in ways that would have seemed implausible eighteen months ago. Intelligence per dollar keeps improving along a steeper curve. These models, in aggregate, present remarkable capability across coding, research, creative work, mathematical reasoning, and business productivity.
But something else is happening that explains the confused reception. The capability space itself is expanding, and it is expanding faster than any single model can cover.
Think of it as the cognitive light cone popularised by biologist Michael Levin. When an intelligent system is narrow, you can measure it with a few benchmarks, optimise it for a handful of tasks, and rank models on a single leaderboard. The surface area is small and manageable. As capability expands, however, the cone widens dramatically. The circumference of what these models can potentially do, spanning coding, creative writing, mathematical proof, visual reasoning, tool use, long-context synthesis, agentic workflows, spreadsheet generation, and 3D visualisation, grows with the radius of intelligence. But the surface area, encompassing the total space of possible applications, edge cases, failure modes, and user requirements, grows quadratically. The space of what we can ask from these systems is expanding faster than the systems themselves. And the ease with which we can evaluate them is shrinking.
This is the geometry the labs are now navigating, whether they articulate it this way or not. Every tuning decision involves trade-offs that cannot be avoided. Optimise for benchmark headlines and you sacrifice creative quality. Optimise for safety and you increase refusals that frustrate users. Optimise for speed and you sacrifice reasoning depth. Optimise for agentic reliability and you sacrifice one-shot performance. The Pareto surface these labs must navigate is vast and getting vaster with each capability gain.
GPT-5.2’s mixed reception is not fundamentally about OpenAI rushing or failing. It is about OpenAI choosing which regions of an expanding surface to optimise under competitive pressure. They picked the parts that make headlines, ARC-AGI, GDP-val, and enterprise benchmarks, while letting other regions degrade or stagnate. The model is genuinely state-of-the-art in some dimensions and a measurable regression in others. Both observations are true because they describe different parts of the cone. You cannot tile a quadratically expanding surface with a linearly growing set of tests.
What does this mean for the future of these systems? The “which model is best?” question is becoming ill-posed, perhaps even meaningless. There is no single frontier anymore in any useful sense. There is a multi-dimensional Pareto surface, and every lab is optimising different regions of it based on their own strategic priorities and customer bases. The race is not to a single finish line that determines a winner. It is to cover the most valuable territory on a map that keeps getting larger.
This is, counterintuitively, good news for the field. It suggests the frontier is genuinely huge and will remain so. It suggests specialisation, or user-controlled compute allocation across different model strengths, is the sustainable path forward rather than a temporary fragmentation. It suggests the competitive dynamics will remain fluid, with no single model able to dominate a space that expands faster than any single entity can fill.
But it also means users must become considerably more sophisticated in how they approach these tools. The era of “just use ChatGPT” for everything is ending. Knowing which model excels at what, understanding how much compute to spend on a given task, and recognising what reliability profile you actually need for your specific workflow are becoming core skills for anyone who wants to use these systems effectively. The cognitive light cone has grown too wide for simple answers or universal recommendations.
Takeaways: GPT-5.2’s mixed reception is not ultimately a story about one model’s quality or one company’s rushed response to competition. It is a story about the geometry of expanding machine intelligence. As AI capability grows, the surface area of what these systems can do, and what we expect from them, grows faster still. No single model can cover that space. The labs are optimising different regions based on different priorities. The benchmarks are measuring shrinking fractions of what matters. And users are left navigating a landscape that is expanding, genuinely powerful, and genuinely difficult to summarise with simple comparisons. This is not a failure of progress. It is the shape progress takes when intelligence stops being narrow.