


Who owns the silicon?
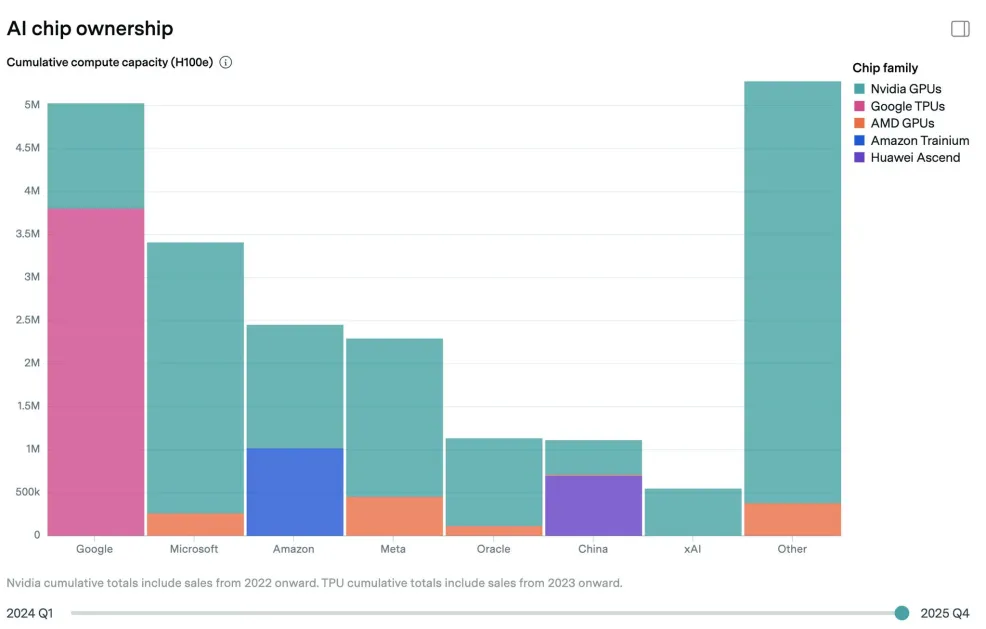
This week’s chart is from Epoch AI’s brand new Chip Owners Explorer. Google dominates global AI compute ownership with roughly 5 million H100-equivalents, more than Microsoft, and far more than Amazon, Meta or Oracle (and the whole of China). But look closely at the colour. That enormous pink block is TPUs, Google’s custom chips. Strip those out and Google’s Nvidia GPU fleet is relatively modest.
This matters because we’re entering the GB200 NVL72 era. Nvidia’s rack-scale Blackwell systems are delivering big gains for Anthropic. Google’s TPU v6 Trillium chips are strong on price-performance and power efficiency, drawing 300W versus Blackwell’s 1,000W+ per chip. Google claims 4x better cost efficiency than H100 for large language model workloads. But the GB200 NVL72 isn’t an H100. It’s a different beast entirely, and Google’s Ironwood (TPU v7) response is only just arriving.
The chart shows Google owns the most AI compute, but compute isn’t static. If Blackwell’s rack-scale architecture delivers for others as it has for Anthropic, then Microsoft, Meta, Amazon and Oracle, all overwhelmingly Nvidia customers, could see their effective compute surge past Google’s installed base.
Owning the most chips isn’t the same as owning the best ones.
Weekly news roundup
AI business news
- Meta’s Muse Spark is here — and it’s closed source (Meta’s first model from its new MSL lab, released April 8, marks a clear break from Meta’s historic open-weights stance. Closed source at launch, though Meta hints at open-weights for future versions.)
- Anthropic buys Coefficient Bio for $400M (Anthropic’s biggest move into biopharma — a stealth startup with fewer than 10 employees from ex-Genentech founders. Extends the Claude Life Sciences line launched in October 2025 and signals Anthropic is willing to make vertical bets, unusual for a lab focused on horizontal capabilities.)
- OpenAI launches $100/month ChatGPT Pro tier with 5x Codex usage (OpenAI slots a mid-tier between $20 Plus and $200 Pro, mirroring Anthropic’s Max pricing. 10x promotional boost through May 31. OpenAI says Codex usage has risen 70% month-on-month — a direct competitive response to Claude Code.)
- Shopify launches AI Toolkit for Claude Code, Cursor, Codex, and VS Code (Shopify’s official toolkit, open-sourced under MIT, bundles 16 skill files covering the Shopify platform — agents can now build apps and manage stores via natural language. A clear signal that e-commerce platforms now treat agent-readiness as a core surface area.)
- Milla Jovovich launches MemPalace AI memory tool (The Hollywood actress pivoting to AI startups is less notable than what MemPalace is — a consumer memory layer for AI agents, the latest bet that persistent context becomes the product moat as models themselves commoditise.)
AI governance news
- CIA trusts AI to help analyse intel from human spies (The US intelligence community’s most sensitive data stream — HUMINT — is now being processed through AI. A significant escalation from the previous lines around signals intelligence and open source.)
- Gen Z workers actively sabotaging their company’s AI rollout (Fortune’s reporting on deliberate resistance — deleting training data, feeding bad prompts, refusing to document workflows — is the first organised evidence that the displacement anxiety we’ve written about is now expressing itself as shop-floor action.)
- Elon Musk’s xAI sues Colorado over AI anti-discrimination law (xAI filed in US District Court challenging Senate Bill 24-205, arguing the disclosure requirements violate the First Amendment and create a “patchwork” of conflicting state rules. The first AI lab to move the permissionless-innovation-vs-accountability fight from the legislature into the courtroom.)
- Nineteen new US state AI bills passed into law in recent weeks (State-level AI legislation has jumped from 6 new laws to 25 since mid-March, with 27 more bills through both chambers. Transparency disclosures, chatbot rules, deepfakes and health-insurance prior-authorisation restrictions dominate. The federal preemption framework is running into a wall of already-enacted state law.)
- Maine sends AI therapy chatbot ban to governor (Maine follows Illinois in banning AI-based therapy services, with Missouri pursuing a similar ban through its omnibus healthcare bill. This is rapidly becoming the first clear category of AI-specific prohibition in US law.)
AI research news
- Memento: Microsoft’s chain-of-thought memory framework (Microsoft’s Memento extends the effective output length of reasoning models by splitting chain-of-thought into blocks and summaries, evicting older blocks from the KV cache to continue from the summary in shorter context — a direct attempt to solve context rot in long-running agent deployments.)
- DEMASK: dependency-guided parallel decoding for diffusion language models (A lightweight dependency predictor that attaches to the final hidden states of a diffusion LM, achieving 1.7–2.2x speedup on Dream-7B while matching or improving accuracy. Diffusion LMs are closing the efficiency gap with autoregressive models.)
- daVinci-MagiHuman: single-stream audio-video generative foundation model (SII-GAIR and Sand.ai’s open 15B model synchronises text, video and audio through a single Transformer — a structural simplification over the cross-attention architectures that currently dominate. Generates 5 seconds of 256p video in 2 seconds on a single H100.)
- BloClaw: an omniscient multi-modal agentic workspace for scientific discovery (A unified operating system for AI4S that replaces fragile JSON tool-calling with an XML-Regex dual-track protocol (0.2% error rate vs 17.6% for JSON), with runtime state interception via Python monkey-patching. Benchmarked across cheminformatics, protein folding and molecular docking.)
- Ontology-constrained neural reasoning in enterprise agentic systems (A neurosymbolic architecture implemented in Foundation AgenticOS, using a three-layer ontological framework to ground LLM reasoning in formal domain knowledge. Evaluated across 600 runs in five industries, showing significant gains on regulatory compliance and role consistency — greatest where LLM parametric knowledge is weakest.)
AI hardware news
- Amazon’s ‘Project Houdini’ reinvents how data centres are built (AWS’s new modular approach is aimed squarely at the build-time problem — traditional hyperscale data centres take years to stand up, and AI demand can’t wait that long. The first hyperscaler to crack this wins the next five years.)
- OpenAI pauses UK investment deal over energy costs and regulation (OpenAI publicly walking away from UK infrastructure investment over energy prices and regulatory friction is a direct rebuke — and a warning to European governments that the compute they think they can host is far more mobile than they assumed.)
- TSMC’s packaging bottleneck: even US-made chips take a round trip to Taiwan (CNBC’s deep dive on advanced packaging reveals that Nvidia has reserved the majority of TSMC’s most advanced capacity, and even US-fabricated chips still need to fly to Taiwan for packaging. A stark reminder that reshoring compute is more complicated than onshoring wafer production.)
- Half of planned US data centre builds delayed or cancelled (Power infrastructure shortages and Chinese component bottlenecks are biting hard. Only one-third of the 12 GW of capacity expected to come online in 2026 is currently under active construction. The AI build-out is running into physical reality faster than most forecasts assumed.)
- ITIF: Four reasons new AI data centres won’t overwhelm the electricity grid (A rare contrarian voice against the power-crisis consensus. ITIF argues demand-side flexibility, non-coincident peaks, hyperscaler on-site generation and accelerating grid investment mean the doom-scenario numbers overstate the risk. A useful counterweight given how much policy is being driven by worst-case forecasts.)



