


Task completion accelerates beyond predictions
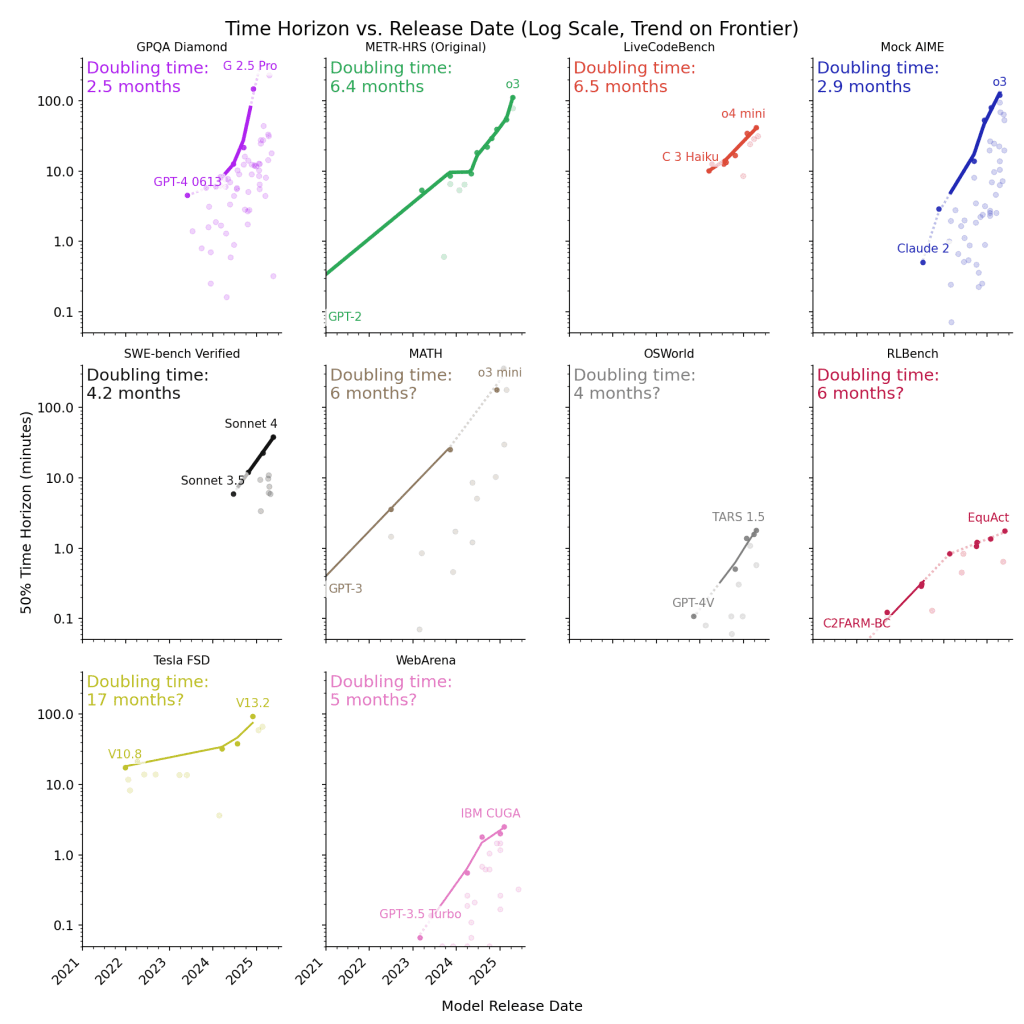
METR have updated their analysis of AI’s accelerating capability to handle longer tasks across domains. The graphs show doubling times for completable task length across common benchmarks. It indicates around 2.5 to 6 months for intellectual work like coding and maths. More physical tasks like self-driving improve more slowly at 17 months. Frontier models now tackle 100+ minute tasks reliably, approaching half-day professional work. The exponential growth suggests we’re months, not years, from AI managing day-long projects.
Weekly news roundup
This week’s developments showcase intense competition for AI talent driving unprecedented valuations, regulatory shifts targeting AI governance, and significant advances in agentic AI systems whilst infrastructure challenges mount from environmental costs to geopolitical tensions.
AI business news
- Meta, Google AI talent grab may spur a Silicon Valley rethink (Shows how intense competition for AI talent is reshaping tech industry dynamics and compensation structures.)
- Microsoft’s Copilot is getting lapped by 900 million ChatGPT downloads (Highlights the consumer adoption race in AI and implications for enterprise AI strategies.)
- Anthropic hired back two of its employees — just two weeks after they left for a competitor (Demonstrates the fierce talent war and importance of retention in AI companies.)
- AWS goes full speed ahead on the AI agent train (Shows how cloud providers are betting big on agentic AI as the next major platform shift.)
- Mira Murati’s Thinking Machines Lab is worth $12B in seed round (Reveals the massive valuations and capital flowing into new AI ventures from high-profile founders.)
AI governance news
- White House prepares executive order targeting ‘woke AI’ (Signals potential regulatory shifts that could impact AI development and deployment practices.)
- US authors suing Anthropic can band together in copyright class action, judge rules (Important legal precedent for AI training data and copyright issues affecting model development.)
- Amazon’s (AMZN) carbon emissions climbed 6% in 2024 on data center buildout (Highlights the environmental costs of AI infrastructure expansion.)
- LLMs are changing how we speak, say German researchers (Shows the broader societal impacts of AI on human communication patterns.)
- OpenAI and Anthropic researchers decry ‘reckless’ safety culture at Elon Musk’s xAI (Reveals internal industry concerns about AI safety practices and responsible development.)
AI research news
- Kimi K2: open agentic intelligence (Introduces new open-source approaches to building autonomous AI agents.)
- A survey of context engineering for large language models (Provides comprehensive overview of techniques to improve LLM performance through better context management.)
- Future of work with AI agents (Stanford research offering data-driven insights into how AI agents will transform workplace dynamics.)
- Test-time scaling with reflective generative model (Presents novel approach to improving model performance during inference without retraining.)
- Towards agentic RAG with deep reasoning: a survey of RAG-reasoning systems in LLMs (Explores the convergence of retrieval-augmented generation with reasoning capabilities.)
AI hardware news
- How Nvidia’s Jensen Huang persuaded Trump to sell A.I. chips to China (Reveals the complex geopolitics and business considerations shaping AI hardware access.)
- TSMC to speed up construction of US chip plants by ‘several quarters’ (Shows acceleration of AI chip manufacturing capacity in the US market.)
- China powers AI boom with undersea data centers (Demonstrates innovative infrastructure approaches to support AI computing demands.)
- Nvidia’s resumption of H20 chip sales related to rare-earth element trade talks (Highlights the interconnected nature of AI supply chains and resource dependencies.)
- Risk of undersea cable attacks backed by Russia and China likely to rise, report warns (Warns of emerging threats to critical AI and internet infrastructure.)



