

This week we look at:
- GPT-5.2’s mixed reception and what it reveals about AI’s frontier
- The first year of agents according to new large-scale research
- Where $37 billion in enterprise AI spending is actually going
GPT-5.2 and the contours of progress
OpenAI’s GPT-5.2 is here, and it arrives under unusual circumstances. The company declared “Code Red” in early December after Google’s Gemini 3 landed with record benchmark scores and Anthropic’s Claude Opus 4.5 quickly became the favourite among developers for its reliable tool use and natural coding flow. Sam Altman’s internal memo halted work on ads, shopping tools, and health agents to focus all resources on a competitive response. The result shipped on December 11th, just weeks after 5.1.
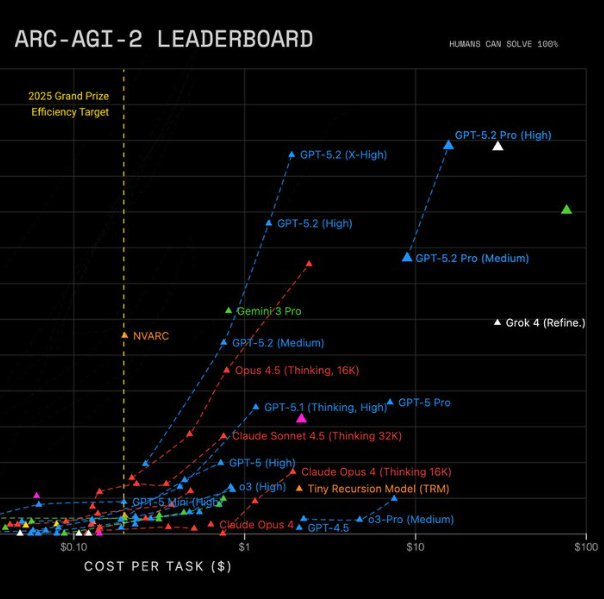
The model brings a 400,000 token context window, a claimed 38% reduction in hallucinations, and three tiers designed for different needs: Instant for speed, Thinking for balanced reasoning, and Pro for deep, expensive cognition. The benchmarks look strong. On ARC-AGI-2, a test of abstract visual reasoning that stumped models just months ago, GPT-5.2 Pro scores 54.2%, clearing Gemini 3’s 31.1% and Opus 4.5’s 37.6% by a wide margin. On the AIME 2025 maths exam, it hits 100% without using tools. Long-context retrieval approaches perfection at 256,000 tokens. OpenAI’s own GDP-val benchmark, which measures performance on professional knowledge work, shows the model outperforming human experts in 70.9% of comparisons across 44 occupations.
The enterprise pitch is apparent. Microsoft’s Satya Nadella calls it a “turning point” for business workflows, and GitHub has rolled it into Copilot. The pricing, up 17% from GPT-5.1 to $1.75 per million input tokens, signals who the intended customer is. This is a model built for companies with budgets.
But the practitioners who have spent the past 48 hours testing GPT-5.2 are telling a more mixed story. “It’s not very good, is it?” is the verdict from one popular AI podcast within hours of release. Developers are finding tool chaining unreliable. The model can call a tool once without issue, but struggles to chain multiple calls together or recover gracefully from errors. Anthropic’s models, by contrast, seem to have an internal clock, pacing themselves, checking their work, and asking for another pass when needed. GPT-5.2 tries to do everything in one aggressive shot, and when it fails, it just fails. SimpleBench, which tests common-sense spatio-temporal reasoning, shows GPT-5.2 and GPT-5.2 Pro both scoring worse than their GPT-5 counterparts.
Creative users are finding it “soulless.” One tester calls it a “glorified calculator” for novelists. Writing engagement scores trail Anthropic’s Sonnet 4.5 by six points. The safety tuning feels heavy-handed to many, with a general reluctance to commit that degrades capability scores in measurable ways. The model appears to have knowledge it will not use.
Speed remains problematic for the Pro tier. Matt Shumer, an early tester with access to the model before launch, reports that it can “think for a long time and still make a big mistake, wasting a lot of my time.” Theo, a coding-focused YouTuber, describes 30 to 50 minute waits for complex tasks. The ARC Prize team cannot even verify GPT-5.2 Pro’s extra-high reasoning mode on ARC-AGI-2 because the API keeps timing out.
Yet others are genuinely impressed with what they are seeing. For deep research, for complex multi-step reasoning, for processing vast documents, the model delivers capabilities that were not available at any price a year ago. Shumer calls it “the best model in the world” for tasks no other model can touch. Enterprise evaluations in finance and life sciences show meaningful reasoning improvements over previous generations. And the ARC-AGI efficiency gains are remarkable: a year ago, a special preview of OpenAI’s o3 scored 88% on ARC-AGI-1 at $4,500 per task. GPT-5.2 Pro now hits 90.5% at just $11.64, representing a 390x efficiency improvement in twelve months.
So which is it? Best model ever, or rushed disappointment? The answer is both, and this is what matters most about GPT-5.2.
We are reaching the end of 2025 with four big frontier models, Gemini 3 Pro, Claude Opus 4.5, Grok 4.1, and GPT-5.2, that are all genuinely strong. Scaling has not hit any hard wall. Test-time compute, where models spend more inference cycles “thinking” before responding, continues to extend capability in ways that would have seemed implausible eighteen months ago. Intelligence per dollar keeps improving along a steeper curve. These models, in aggregate, present remarkable capability across coding, research, creative work, mathematical reasoning, and business productivity.
But something else is happening that explains the confused reception. The capability space itself is expanding, and it is expanding faster than any single model can cover.
Think of it as the cognitive light cone popularised by biologist Michael Levin. When an intelligent system is narrow, you can measure it with a few benchmarks, optimise it for a handful of tasks, and rank models on a single leaderboard. The surface area is small and manageable. As capability expands, however, the cone widens dramatically. The circumference of what these models can potentially do, spanning coding, creative writing, mathematical proof, visual reasoning, tool use, long-context synthesis, agentic workflows, spreadsheet generation, and 3D visualisation, grows with the radius of intelligence. But the surface area, encompassing the total space of possible applications, edge cases, failure modes, and user requirements, grows quadratically. The space of what we can ask from these systems is expanding faster than the systems themselves. And the ease with which we can evaluate them is shrinking.
This is the geometry the labs are now navigating, whether they articulate it this way or not. Every tuning decision involves trade-offs that cannot be avoided. Optimise for benchmark headlines and you sacrifice creative quality. Optimise for safety and you increase refusals that frustrate users. Optimise for speed and you sacrifice reasoning depth. Optimise for agentic reliability and you sacrifice one-shot performance. The Pareto surface these labs must navigate is vast and getting vaster with each capability gain.
GPT-5.2’s mixed reception is not fundamentally about OpenAI rushing or failing. It is about OpenAI choosing which regions of an expanding surface to optimise under competitive pressure. They picked the parts that make headlines, ARC-AGI, GDP-val, and enterprise benchmarks, while letting other regions degrade or stagnate. The model is genuinely state-of-the-art in some dimensions and a measurable regression in others. Both observations are true because they describe different parts of the cone. You cannot tile a quadratically expanding surface with a linearly growing set of tests.
What does this mean for the future of these systems? The “which model is best?” question is becoming ill-posed, perhaps even meaningless. There is no single frontier anymore in any useful sense. There is a multi-dimensional Pareto surface, and every lab is optimising different regions of it based on their own strategic priorities and customer bases. The race is not to a single finish line that determines a winner. It is to cover the most valuable territory on a map that keeps getting larger.
This is, counterintuitively, good news for the field. It suggests the frontier is genuinely huge and will remain so. It suggests specialisation, or user-controlled compute allocation across different model strengths, is the sustainable path forward rather than a temporary fragmentation. It suggests the competitive dynamics will remain fluid, with no single model able to dominate a space that expands faster than any single entity can fill.
But it also means users must become considerably more sophisticated in how they approach these tools. The era of “just use ChatGPT” for everything is ending. Knowing which model excels at what, understanding how much compute to spend on a given task, and recognising what reliability profile you actually need for your specific workflow are becoming core skills for anyone who wants to use these systems effectively. The cognitive light cone has grown too wide for simple answers or universal recommendations.
Takeaways: GPT-5.2’s mixed reception is not ultimately a story about one model’s quality or one company’s rushed response to competition. It is a story about the geometry of expanding machine intelligence. As AI capability grows, the surface area of what these systems can do, and what we expect from them, grows faster still. No single model can cover that space. The labs are optimising different regions based on different priorities. The benchmarks are measuring shrinking fractions of what matters. And users are left navigating a landscape that is expanding, genuinely powerful, and genuinely difficult to summarise with simple comparisons. This is not a failure of progress. It is the shape progress takes when intelligence stops being narrow.
The dawn of the agentic era
2025 was supposed to be the year we’d all have a “swarm of agents” working for us. That was the promise. The reality, according to new research this week from Harvard and Perplexity, is more modest but the foundations are forming.
The study analysed hundreds of millions of user interactions with Perplexity’s Comet browser agent between July and October 2025. It represents the first large-scale field study of how individuals use general-purpose AI agents. The data suggests that agents are starting to benefit personal productivity beyond the well established chatbot interface:
- Productivity and workflow and learning and research account for 57% of all agentic queries
- Personal use constitutes 55%, professional 30%, educational 16%
- Document editing is the top task overall: Create/edit documents accounts for 6.58% of all agentic queries, making it the single largest individual task.
- Email management is about decluttering, not composing: Search/filter emails (49.1%) and delete/unsubscribe (30.6%) far outpace sending emails (9.6%). People use agents to manage inbox overload rather than write messages.
- Earlier adopters, users in wealthier countries, and knowledge workers in tech, academia, finance, and marketing are most likely to use agents
A separate study we featured in last week’s AI research roundup examined how enterprises build production agents. Researchers from Berkeley, IBM, and Stanford surveyed 306 practitioners and conducted 20 in-depth case studies across 26 industries. The picture that emerges is one of constraint:
- 73% deploy agents primarily to increase productivity and reduce time on manual tasks
- 70% rely solely on off-the-shelf models without any fine-tuning
- 68% execute ten steps or fewer before requiring human intervention
- 74% depend primarily on human-in-the-loop evaluation
- 85% build custom applications rather than using third-party agent frameworks
- 92.5% of deployed agents serve human users, not other AI systems
- Finance and banking lead adoption at 39%
Together, these studies describe where personal and enterprise agents stand today. The technology can more actively drive creation and complex outputs, but ambition is still somewhat limited to extending existing human workflows. Production teams are not building sophisticated autonomous systems. They are building carefully scoped tools with heavy human oversight using off-the-shelf models.
Building multi-agent systems is hard. In new research from Google and MIT also published this week (“Towards a Science of Scaling Agent Systems“) researchers tested 180 configurations across five agent architectures and three model families to determine when multi-agent coordination actually helps. The findings challenge the popular “more agents is all you need” narrative. Centralized coordination improved performance by 81% on parallelizable tasks like financial reasoning. But for sequential reasoning tasks, every multi-agent variant degraded performance by 39-70%. The study identified a critical threshold: once single-agent baselines exceed roughly 45% accuracy, adding more agents yields diminishing or negative returns. Independent agents amplify errors 17 times through unchecked propagation, while centralized coordination contains this to 4.4 times.
Takeaways: The (first) “Year of Agents” has yet to deliver autonomous workers but has augmented many workflows with meaningfully useful agentic automations. The technology functions reliably within careful constraints: few steps, human oversight, simple architectures. The question for 2026 is whether those boundaries can expand without sacrificing the reliability that makes current agents useful. Numerous research papers and projects offer promising approaches for making agents more capable: multi-agent orchestration, self-evolving agents, automated prompt optimisation, and reinforcement learning for tool use. Yet the production data shows almost none of these techniques are being deployed today. The Google/MIT research helps explain why: multi-agent coordination actively degrades performance on sequential reasoning tasks, independent agents amplify errors dramatically, and adding agents to already-capable systems yields diminishing returns. Getting coordination right requires careful matching of architecture to task structure, not simply throwing more agents at problems. Teams that master this matching, learning when coordination helps and when it harms, will be best positioned to move these innovations from lab to production in the year ahead.

Enterprise AI breaks records
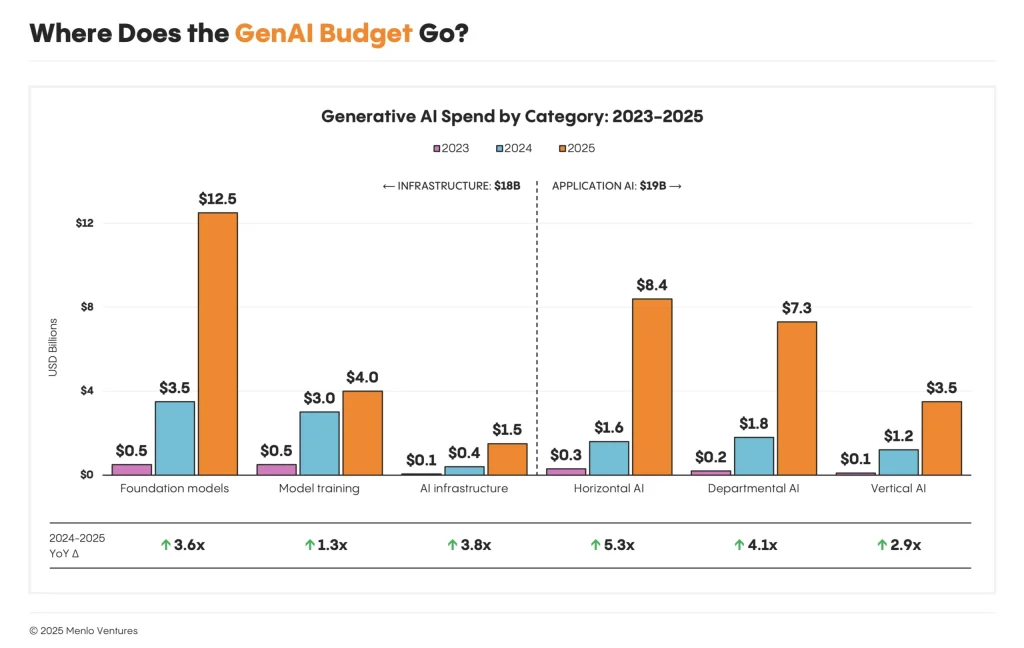
This chart shows where enterprise generative AI budgets are actually flowing, dividing $37 billion of 2025 spending into six categories across two layers. The data comes from Menlo Ventures’ third annual State of Generative AI in the Enterprise report, which surveyed approximately 500 U.S. enterprise decision-makers and combined their insights with a bottoms-up market model spanning model APIs, infrastructure, and applications.
On the left of this spectrum, infrastructure spending totals $18 billion, dominated by foundation model APIs at $12.5 billion, with model training ($4 billion) and AI infrastructure ($1.5 billion) making up the rest. On the right, application spending reaches $19 billion, split between horizontal AI tools like ChatGPT Enterprise and Claude for Work ($8.4 billion), departmental solutions led by coding tools ($7.3 billion), and vertical AI targeting industries like healthcare ($3.5 billion).
The year-on-year growth rates beneath each bar reveal where momentum is strongest. Horizontal AI grew 5.3x, followed by departmental AI at 4.1x, while foundation models grew 3.6x despite already being the largest category by absolute spend. Model training, by contrast, grew just 1.3x, suggesting that enterprises are increasingly consuming pre-trained models rather than building their own (a finding that supports the data on LLM usage in our piece this week on the first year of agents).
Three years after ChatGPT’s launch, this $37 billion market has become the fastest-scaling software category in history.
Weekly news roundup
This week’s news highlights major corporate AI partnerships and pricing strategies, growing regulatory tensions between governments and tech giants, advances in agentic AI research, and significant hardware deals as companies race to secure AI infrastructure.
AI business news
- Google DeepMind partners with UK government to deliver AI (Signals how governments are increasingly collaborating directly with leading AI labs to accelerate national AI capabilities.)
- Zoom AI sets new state-of-the-art benchmark on Humanity’s Last Exam (Demonstrates that enterprise software companies are now competing at the frontier of AI reasoning benchmarks.)
- Google debuts ‘Disco,’ a Gemini-powered tool for making web apps from browser tabs (Shows the continued push toward AI-assisted application development that could democratise software creation.)
- Salesforce opts for seat-based AI licensing (Reveals emerging business models for AI agents and the commercial challenges of pricing autonomous systems.)
- Oracle slumps as gloomy forecasts, soaring spending fan AI bubble worries (Highlights growing investor concerns about the sustainability of massive AI infrastructure investments.)
AI governance news
- States defiant in face of Trump’s AI executive order (Illustrates the fragmented regulatory landscape emerging in the US as states push back against federal AI policy.)
- Google removes AI videos of Disney characters after cease and desist (Underscores the unresolved intellectual property tensions between AI platforms and content owners.)
- Big Tech warned over AI ‘delusional’ outputs by US attorneys general (Shows regulators taking action on AI hallucinations and misinformation, a key concern for enterprise deployments.)
- BA boss fears AI agents could make brands invisible (Raises critical questions about how AI intermediaries may reshape consumer relationships and brand value.)
- EU will investigate Google over how it uses online content for AI training (Signals continued European regulatory scrutiny of AI training data practices under existing competition law.)
AI research news
- DeepCode: open agentic coding (Presents an open-source approach to autonomous coding agents, relevant for those building AI-assisted development tools.)
- Native Parallel Reasoner: reasoning in parallelism via self-distilled reinforcement learning (Offers new techniques for improving reasoning efficiency in large language models.)
- Large Causal Models from Large Language Models (Explores extracting causal reasoning capabilities from LLMs, crucial for reliable decision-making systems.)
- ProAgent: harnessing on-demand sensory contexts for proactive LLM agent systems (Advances agentic AI by enabling models to proactively gather contextual information.)
- A comprehensive survey on integrating large language models with knowledge-based methods (Provides a valuable overview of hybrid approaches combining LLMs with structured knowledge systems.)
AI hardware news
- Intel is said to near $1.6 billion deal for chip firm SambaNova (Demonstrates Intel’s aggressive moves to strengthen its AI chip portfolio through acquisition.)
- Trump gives Nvidia the OK to sell advanced AI chips to China (Marks a significant shift in US export controls with major implications for global AI competition.)
- Nvidia-backed Starcloud trains first AI model in space, orbital data centres (Showcases experimental approaches to addressing AI compute constraints through novel infrastructure.)
- Broadcom reveals its mystery $10 billion customer is Anthropic (Confirms the massive scale of infrastructure investment by leading AI labs.)
- Rivian is building its own powerful AI chips for autonomous driving (Shows automotive companies following Tesla’s lead in developing custom silicon for AI workloads.)



