

This week we look at:
- Google’s Gemini 3 crushing benchmarks and reshaping AI competition
- Whether Nvidia’s quarterly results signal strength or bubble
- AI coding models approaching full-day autonomous development capabilities
Gemini 3 leaves competitors scrambling
When a screen grab of Gemini 3 benchmarks leaked ahead of launch, the numbers appeared unrealistic. A 45% score on ARC-AGI-2, triple the previous best. An Elo above 1500 on LMSYS Arena. Over 90% on GPQA Diamond. The numbers looked like wishful thinking from overeager AI enthusiasts. Then Google officially released the model, and the scores proved accurate. It appeared to have dealt a hammer blow to the competition. Yet whilst the benchmarks tell a story of technical dominance, the reality of high-level intelligence is always more complicated.
Gemini 3 Pro is a very large general model, (estimates suggest multi-trillions of parameters), it has a one‑million‑token context window and can generate at around 120+ tokens per second which is surprisingly fast for its size. On price, Google has kept the base Pro tier in line with the market: $2 per million input, and $12 per million output tokens. If benchmarks were infallible, this model would be untouchable. On Humanity’s Last Exam, it reached 41% where most competitors struggle to break 30%. These aren’t incremental improvements; they represent capability jumps that shouldn’t be possible if scaling had truly hit a wall.
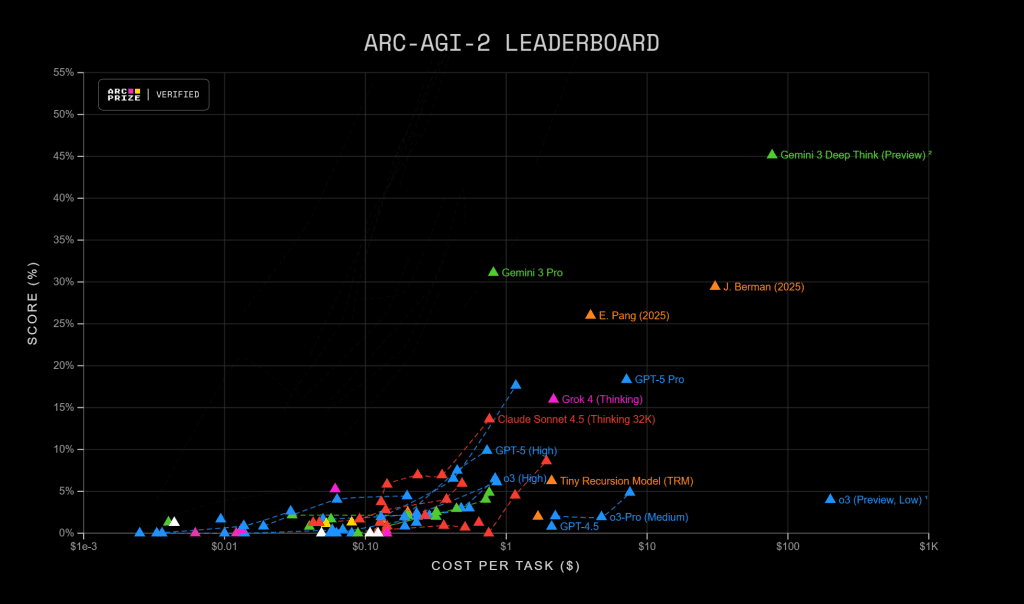
On the ground, many users and creators have been instantly impressed. Developers talked about single‑shot complex software outputs, 3D user interfaces, compiler designs, or advanced ray‑tracing and more. Our own experience at ExoBrain has been of deep knowledge and a bigger scope to accelerate software creation, but in some cases frustrating intransigence and slightly hallucinatory behaviours. Gemini’s deployment has not been entirely smooth. Some users reported being silently downgraded from 3.0 to 2.5 mid‑session. AI Studio enforces a 50‑message daily cap that kills sustained experiments. Tool calling can be flaky. The model can over‑edit code, chew through context for no good reason. Its deep and powerful but serving it at scale is a huge challenge.
Hot on the heels of Gemini 3, Google has released Nano Banana Pro, their image generation model powered by the same underlying architecture. The model produces photorealistic images at 2048×2048 resolution with what Google calls “unprecedented coherence” in text rendering and complex scene composition. Early users report it handles intricate prompts that typically confuse other models, particularly those requiring specific spatial relationships or accurate text within images. This appears to be another major leap in detail and steerability. An infographic generated from this article shows off its incredible layout and text capabilities:

The natural question is how Google pulled off these jumps, and can the others react. DeepMind’s Oriol Vinyals’s answer was simple: better pre‑training and better post‑training. He described the gap between 2.5 and 3.0 as the biggest they have seen yet, with “no walls in sight”, and called post‑training a greenfield. That runs directly against the recent line from Ilya Sutskever that “pre‑training as we know it will end”. For now, plain scaling plus smarter training still buys you a lot.
Underneath that, Google has three structural advantages it is now starting to flex. First, the DeepMind acquisition and re-organisation is providing world‑leading research talent now plugged straight into Google’s product surfaces. Demis Hassabis is proving to be a capable leader. Second, Sergey Brin’s return to hands‑on work gave the AI effort focus. Internally, that shows up as faster iteration, more tolerance for risk, and less of the committee‑driven hesitation about shipping frontier models into flagship products that previously held Google back. Third, and most decisive, is hardware. Gemini 3 was trained end‑to‑end on Google’s own Tensor Processing Units rather than NVIDIA GPUs. The latest TPU generation, Ironwood, can be wired into clusters of more than nine thousand chips, delivering around ten times the performance of older parts whilst using a fraction of the power per operation.
That control over the silicon layer makes the full‑stack story credible. Google is not just dropping Gemini 3 into an app. It is pushing it into Search, into the API, Android, NotebookLM, AI Studio into Docs and Gmail, (and into Antigravity, its agent‑first development environment based on the part of Windsurf they recently acquired). This is the real flex: a single model line, trained on in‑house chips, surfacing across billions of users and most of the company’s revenue engines.
An internal memo from Sam Altman reportedly warned OpenAI staff to expect “temporary economic headwinds” from Google’s progress, and conceded that Gemini 3 “seems to have surpassed OpenAI in terms of development methods”. He also noted that Google’s ability to integrate Gemini across Search, YouTube and consumer products on day one is not something OpenAI can match right now. OpenAI has API reach and Microsoft backing, but it does not own the operating systems, browsers, or default search box.
But the sheer scale of the bar Google has set will give competitors pause. Google’s infrastructure leaders talk internally about doubling compute capacity roughly every six months and chasing a thousand‑fold increase over four to five years while keeping unit costs flat and power use under control. Scaling large models is not “over”. If you have the focus, data, and hardware, you can dominate.
Takeaways: Google is now flexing its full stack: DeepMind research, founder backing, custom TPUs, and instant integration across search, workspace, apps and developer tools. For organisations evaluating AI providers, Gemini 3 presents a compelling case as the workhorse model for most demanding applications, particularly those requiring complex reasoning or massive context windows. Google’s ability to deploy at scale whilst others struggle with availability suggests they’ve solved not just the training challenge but the harder problem of inference economics. As Altman’s memo acknowledges, Google has turned diversity into structural superiority. The question for competitors isn’t whether they can match Gemini 3’s benchmarks, but whether they can afford to serve comparable models at Google’s scale. The race has entered a new phase where raw intelligence matters less than the ability to deploy it economically.
Bulls and bears battle over Nvidia’s billions
Nvidia’s third-quarter results landed with spectacular force: $57 billion in revenue, up 62% year-on-year, with data centre revenue hitting $51.2 billion. The company guided fourth-quarter revenue to $65 billion, comfortably above the $62 billion analysts expected. CEO Jensen Huang declared Blackwell sales “off the charts” and cloud GPUs “sold out”. Gross margins held steady at 73.4%, and the company returned $37 billion to shareholders through the first nine months of fiscal 2026.
The bulls argue these numbers validate genuine AI demand. Revenue growth remains extraordinary, margins are holding firm, and forward guidance suggests sustained momentum. Major hyperscalers continue massive infrastructure investments, with Nvidia securing partnerships worth hundreds of thousands of GPUs with Microsoft, Amazon, Oracle and others. The company’s networking business doubled, proving demand extends beyond just chips. Supporters point to broadening adoption across industries and geographies as evidence that AI transformation is real, not speculative. Wall Street’s major banks reinforced this view: Goldman Sachs raised its price target to $250, JPMorgan to $250, and Bank of America to $275, all citing sustainable competitive advantages and potential upside to the $500 billion data centre revenue projection.
The bears see troubling patterns beneath the surface. Michael Burry, of The Big Short fame, highlights that Nvidia spent $112.5 billion on buybacks since 2018 yet shares outstanding actually increased by 47 million, suggesting true owner earnings are half what they appear. Four customers now represent 61% of revenue, up from 56% last quarter, exposing massive concentration risk. The $26 billion in chip leasing arrangements, double from Q2, indicates Nvidia is financing its own customers’ purchases. Peter Berezin’s analysis projects hyperscalers will hold $2.5 trillion in AI assets by 2030, generating $500 billion in annual depreciation expense, exceeding their combined profit forecasts.
Three critical components are driving this forward. Circular financing sees tech giants investing in AI startups who then purchase services from those same investors, creating synthetic demand loops. Depreciation manipulation allows hyperscalers to extend equipment lifecycles from three to six years, understating current expenses by potentially 50%. Nvidia would argue that their CUDA software layer is extending the usable life of older GPUs. Finally, as we highlighted last week, credit expansion through both corporate bonds and private lending is now funding the buildout, adding leverage to an already concentrated system.
AI is unquestionably transformative. The infrastructure is being built at unprecedented speed and cost, but whether end-user economics in the short term will justify these investments and sustain Nvidia’s growth remains unproven.
Takeaways: Google’s CEO Sundar Pichai has been frank about bubble worries but blunt on the alternatives: underinvesting is the bigger risk when cloud revenue is growing by a third each year and the backlog is already massive. McKinsey now estimates $7 trillion in data centre investment is needed by 2030 to meet projected demand. For the rest of the economy, the opportunity is equally stark. These hyperscalers aren’t just building for themselves; they’re creating the infrastructure that will ultimately enable every business to access AI capabilities without prohibitive capital requirements. But the current dynamics mean that the fate of Western capitalism may well depend on successfully translating this AI investment into productivity gains that justify the expense. If means to deploy, unlock and drive AI adoption are perfected, enabling widespread economic transformation, we’ll see huge productivity benefits. If we fail, we’re looking at the largest capital misallocation in history, with debt-laden hyperscalers and the US economy bearing catastrophic losses. The next twelve months will prove crucial in this phase of the AI revolution.

Agents code all day long

This chart tracks the autonomous coding capabilities of OpenAI’s models from 2019 through to 2026, measured using METR’s “time horizon” metric, the length of human-equivalent tasks that AI agents can complete with 50% success. GPT-5.1-Codex-Max, released this week achieves a time horizon of approximately 2 hours 42 minutes, continuing a remarkably consistent trend that has seen capabilities double roughly every 202 days since 2018. See the full METR analysis.
This appears to be the first frontier coding model genuinely capable of handling all-day coding tasks, with internal testing showing completion of projects running over 24 hours. The timing of OpenAI’s release, just one day after Google launched Gemini 3.0, suggests competitive dynamics remain intense in the race to dominate AI coding capabilities. However, the release also reflects OpenAI’s sustained focus on agentic coding systems, with the model featuring new “compaction” technology that allows it to process millions of tokens whilst maintaining context over extended sessions. METR’s extrapolation suggests that by May 2026, on-trend development could yield models with a time horizon approaching 13 hours.
Weekly news roundup
This week’s developments show intensifying competition in open-source AI models, growing concerns about AI safety particularly for vulnerable users, and massive infrastructure investments signalling long-term confidence in AI’s transformative potential.
AI business news
- Ai2 releases Olmo 3 open models, rivaling Meta, DeepSeek and others on performance and efficiency (Shows the accelerating pace of open-source model development challenging commercial offerings and democratising access to advanced AI capabilities.)
- Poland economy under pressure from AI and soaring wages (Illustrates how AI automation is creating economic pressures in emerging markets, relevant for understanding global AI adoption patterns.)
- Adobe, Qualcomm partner with Humain on generative AI for Middle East (Highlights regional AI initiatives and how major tech companies are localising AI solutions for different markets.)
- AlphaXiv raises $7M in funding to become the GitHub of AI research (Points to growing infrastructure for collaborative AI research, potentially accelerating innovation through better knowledge sharing.)
- Report: Startup co-led by Jeff Bezos raises $6.2B to develop ‘AI for the physical economy’ (Demonstrates massive investment in applying AI to real-world physical systems, beyond digital applications.)
AI governance news
- Teens seek mental-health help from chatbots. That’s dangerous, says new study (Critical safety concern showing unintended consequences of AI adoption in sensitive areas like mental health support.)
- White House weighs challenge to state-level AI rules (Indicates emerging regulatory tensions between federal and state authorities that could shape AI deployment frameworks.)
- Scoop: White House moves to block bill restricting AI chip exports (Shows ongoing geopolitical tensions around AI hardware access and potential impacts on global AI development.)
- Boffins build ‘AI kill switch’ to thwart unwanted agents (Represents practical safety measures being developed to control AI systems, addressing alignment concerns.)
- Kremlin says Vladimir Putin does not use AI himself, but that officials who work for him do (Offers insight into how different governments are approaching AI adoption at leadership levels.)
AI research news
- Early science acceleration experiments with GPT-5 (Reveals potential capabilities of next-generation models in advancing scientific research and discovery.)
- Reasoning via video: The first evaluation of video models’ reasoning abilities through maze-solving tasks (Explores multimodal AI capabilities combining visual understanding with logical reasoning.)
- Think, speak, decide: Language-augmented multi-agent reinforcement learning for economic decision-making (Shows advances in AI agents for complex economic modelling and decision support systems.)
- MiroThinker: Pushing the performance boundaries of open-source research agents via model, context, and interactive scaling (Demonstrates progress in autonomous AI research assistants that could accelerate scientific discovery.)
- P1: Mastering physics olympiads with reinforcement learning (Showcases AI’s growing ability to solve complex physics problems, relevant for scientific and engineering applications.)
AI hardware news
- US, Taipei laud opening of Google’s new Taiwan AI engineering centre (Highlights strategic positioning in the global AI supply chain and talent competition.)
- AI data centers are banging on crypto’s door (Shows how AI infrastructure demands are repurposing existing computing resources from cryptocurrency mining.)
- SoftBank to invest $3 billion in Ohio factory for OpenAI data center (Demonstrates massive capital commitments to AI infrastructure and regionalisation of compute resources.)
- Foxconn-Nvidia $1.4 billion Taiwan supercomputing cluster to be ready by H1 2026, Foxconn says (Indicates rapid scaling of AI hardware manufacturing capacity to meet growing demand.)
- UK plans £10 billion Wales data-centre hub in AI push (Shows national-level infrastructure investments to compete in the global AI race.)



