

This week we look at:
- World models versus language as paths to spatial intelligence
- GPT-5.1’s adaptive reasoning and new personality system
- Hyperscalers hiding AI infrastructure debt through financial engineering tactics
Wordsmiths in the dark
This week saw visual AI and world models dominate headlines, with three announcements converging on the same idea: AI needs to understand physical space, not just language.
Fei-Fei Li, whose ImageNet work helped kick-start modern computer vision in the early 2010s, launched Marble, the first product from her new company, World Labs. Marble turns text, images, or video into interactive 3D environments, with editable objects and exportable assets. Li built the company with the researchers behind Neural Radiance Fields (NeRFs), the approach that turns 2D images into 3D scenes.
Google DeepMind, meanwhile, announced SIMA 2, an AI agent powered by Gemini that learns to act inside 3D virtual worlds. SIMA has further potential when paired with GENIE, their earlier model that generates game-like environments from text prompts. GENIE builds the worlds; SIMA moves through them and learns, creating its own training curriculum by inventing harder and harder tasks. The perfect real-world training environment.
Li released a 6,000-word manifesto alongside Marble. Her argument, punctuated with many compelling examples, is that spatial intelligence came hundreds of millions of years before language, and our current systems are “wordsmiths in the dark”; brilliant with symbols, but detached from the physical world. And fundamentally limited. She positions spatial intelligence as the scaffolding of cognition. From pouring coffee to weaving through a crowd, we lean on an internal model of objects, forces, and consequences.
ImageNet, in this story, was the proof point that with neural networks, vision could also be learned from data at scale, not hard-coded. When Geoff Hinton’s AlexNet team crushed image recognition benchmarks in 2012 using ImageNet (and found new potential in Nvidia gaming chips), it made large-scale visual learning credible. Marble and world models are framed as the next big step: from recognising what’s in a scene to simulating how it might unfold.
We also learnt this week that Yann LeCun is reportedly leaving Meta to build his own world model company. He has been clear for years that language models are not enough, arguing that real intelligence requires understanding physics and causality, not just patterns in text. He recently joked that before we worry about controlling superhuman AI, “we need to have the beginning of a hint of a design for a system smarter than a house cat.” His criticism mirrors Li’s: today’s LLMs talk cleverly about the world but don’t embody it.
So, on one side you have Li and LeCun, both pushing hard on spatial intelligence and world models. On the other, a quieter camp suggests the “language versus space” framing might be wrong from the start.
Christopher Summerfield, a neuroscientist at Oxford and former DeepMind researcher, admits he was “really shocked” when language models started showing strong reasoning abilities without any visual input. His work (and recent book These Strange New Minds) suggests that both human brains and LLMs learn similar abstract representations. In one example, he found “Christmas neurons” in AI models that activate for things like trees, sledges, and rituals that look nothing alike but share conceptual links. These abstractions emerged from text alone. Language, it seems, contains far more structure about the world than we expected.
If there’s a figure from history that is a perfect case study for this debate, it is Helen Keller. Born in 1880, she lost both her sight and hearing before the age of two and yet became a respected writer and thinker. Critics claimed her knowledge was “second-hand”, that she could not truly understand visual ideas. Yet she discussed colours she never saw and places she never visited, using language to connect to a shared conceptual world. Her story suggests we must already carry some kind of internal structure for objects and relations before language arrives, but once some form of language attaches to that structure, it becomes the main medium of thought.
Nick Chater and Morten Christiansen, who have studied language for decades and who recently published a fascinating book; The Language Game, push this further. They argue language is not a fixed code with a buried grammar waiting to be decoded, but an endless game of charades played over generations. Meaning is improvised, not retrieved. Their “Vocalisation Challenge” showed that people around the world could invent and understand sounds for concepts like “tiger” or “water” with no visual grounding. Sound patterns alone carried meaning.
We thus end up with a strange tension. If a deaf-blind person can become a deep thinker through language alone, if neuroscience finds that brains and LLMs share similar abstract structures, and if communication can emerge from sound without any visual cue, then the demand that AI must be embodied starts to look less clearcut.
The resolution may be that spatial and linguistic intelligence are not rivals at all, but different projections of a deeper world. Language evolved to talk about a shared physical and social reality. Spatial reasoning shapes so many of our metaphors; “higher status”, “deeper questions”, “close relationships”. Trying to separate the two may be like arguing whether a map is about symbols or its geometry.
Helen Keller did not lack spatial intelligence; she modelled the world through touch, motion, and language. She could navigate spaces, sculpt, and reason about objects. LLMs may be doing something similar but from the opposite direction: inheriting a compressed, textual record of humanity’s interaction with the world. When they reason about packing boxes in a van or laying out a floor plan, they are tapping into that shared encoded fabric rather than simulating physics directly.
Li is right that today’s AI still struggles with many physical tasks. Robots remain clumsy; virtual agents are brittle. As we see with DeepMind’s SIMA training itself to better understand its environment; an environment generated by GENIE the spatial dimension provides a new and limitless source of training data. But Keller’s achievements and Summerfield’s work both suggest that intelligence is not tied to any single modality. It emerges from the structures we can represent and manipulate, whether those come in through sight, sound, touch, or text scraped from the Internet. LLMs may not yet “understand” the world in a human sense, but they are already a surprising window into this deeper fabric.
Takeaways: It is understandable that Li and LeCun continue to push world models, spatial reasoning, and embodiment as the missing jigsaw pieces, not least because their framing also helps them stand out in a crowded research (and funding) landscape. Human intelligence seamlessly integrates both, and truly general AI likely must do the same. The rush toward world models represents genuine technical advancement, but language models have already inherited millennia of compressed spatial understanding through text. As these approaches converge, with language models gaining 3D capabilities and world models incorporating semantic reasoning, the distinction between linguistic and spatial intelligence may prove to be an artificial boundary.
GPT-5.1 adapts its thinking
OpenAI hurriedly released GPT-5.1 this week, perhaps moving first to head-off the building hype around the yet to emerge Gemini 3.0. It’s a modest update on paper but will change how to get the most from the model in practice.
Here’s a summary of what’s new.
- Adaptive reasoning now spends less effort on simple tasks and more on complex ones, improving speed where it matters.
- Eight personality presets (Default, Professional, Friendly, Candid, Quirky, Efficient, Nerdy, Cynical) that affect content, not just tone.
- GPT-5.1-Codex supports a 400,000-token context window, making whole-codebase reasoning more realistic.
- A new “none” reasoning-effort setting helps avoid overthinking and saves tokens on simple queries.
- Instruction following is more reliable, and as Sam Altman posted on X: “If you tell ChatGPT not to use em-dashes in your custom instructions, it finally does what it’s supposed to do!”
- Writing quality is on par with or better than Claude for creative work.
- Pricing is unchanged.
- GPT-5 models stay in the legacy menu until February 2026.
- Some users report needing prompt tweaks to stop over-analysis on simple tasks.
OpenAI’s updated prompting guide highlights some specific techniques for 5.1:
- Emphasise persistence, not brevity GPT-5.1 tends to be very concise. Tell it to “persist until the task is fully handled end-to-end” and “bias for action” if you want thorough, practical outputs.
- Control verbosity with clear limits It follows length rules exactly. Use concrete ranges like “2–5 sentences” or “6–10 sentences” and state simple rules such as “no before/after pairs” or “at most 1–2 short snippets”.
- Define agent personas in detail Don’t just say “be friendly”. Describe how it should think and prioritise, e.g. “You care about clarity, momentum, and respect measured by usefulness rather than pleasantries.” The model will adjust its whole approach.
- Use metaprompting to debug prompts Paste your system prompt plus examples of failures and ask GPT-5.1 to explain what went wrong. It is good at spotting conflicts like “be concise” versus “be exhaustive” and suggesting targeted changes.
- Add simple planning scaffolds for complex work For multi-step tasks, have it maintain a small list of milestones (2–5 items) with statuses like pending, in progress, complete. This keeps long runs from ending too early.
- Remove contradictions in your instructions Because it follows instructions closely, conflicting guidance leads to odd behaviour. Clean up tensions between autonomy and clarification, short answers versus complete ones, and tool-usage rules.
Takeaways: GPT-5.1 thinks harder when tasks demand it but can still overcomplicate easy problems if you let it. The personality system now affects what it does, not just how it sounds, and the boosted Codex context window makes genuine multi-file reasoning more practical for developers. To get the best from it, you need tighter prompt design, clearer personas, and simple planning structures baked into your instructions.

Data centres become debt mules
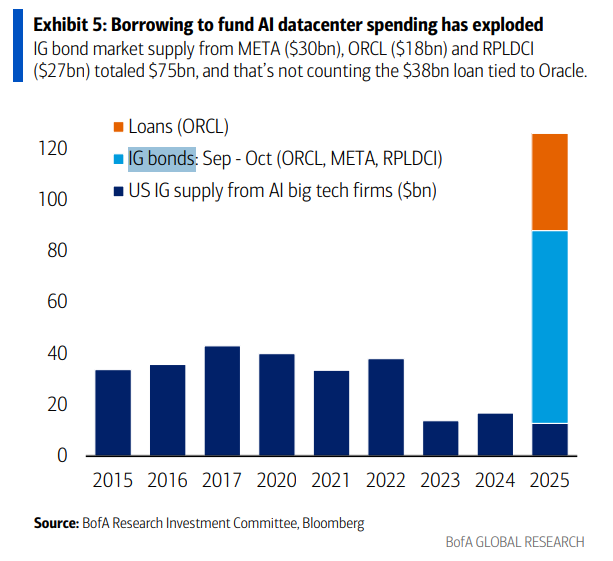
This chart captures the point at which data centre debt decoupled from cash flow in the AI buildout. After a decade where hyperscalers funded infrastructure from their enormous profits, 2025 marks somewhat of a watershed in the race to stay competitive in computational scale.
Hyperscalers generating $700 billion in operating cash flow are already spending $500 billion on AI, now leaving little for continued expansion. Their solution? Special purpose vehicles that keep debt off balance sheets. Meta’s $30 billion Hyperion facility sits in an SPV with Blue Owl, transforming capital expenditure into operating leases. These “debt mules” now carry obligations that parent companies can theoretically walk away from.
Adding to the precarity, Michael Burry has made the headlines this week with his Palantir Big Short 2.0 and accusations that the hyperscalers are extending depreciation schedules to 5-6 years for GPUs that can burn out in 18-24 months running intensive AI workloads. When debt servicing relies on profits against understated depreciation, the financial engineering becomes more critical than the technical innovation it funds. Technology, real estate and complex debt… what could possibly go wrong? But, as we’ve said before, no one can stop spending, or now borrowing, because what if a competitor achieves AGI first?
Weekly news roundup
This week saw massive valuations for AI startups, growing infrastructure investments, and increasing focus on security and governance challenges as the industry matures.
AI business news
- Murati’s Thinking Machines in funding talks at $50 billion value (Shows the extraordinary valuations AI companies are achieving and the continued investor confidence in foundational AI development.)
- AI startup Cursor raises $2.3 billion round at $29.3 billion valuation (Demonstrates the massive capital flowing into AI coding assistants and their potential to transform software development workflows.)
- Yann LeCun’s exit highlights tensions in Meta’s shifting AI strategy (Reveals internal disagreements at major tech companies about AI development approaches and the balance between research and product deployment.)
- AI bubble is ignoring Big Short Michael Burry chip depreciation fears (Highlights potential financial risks in AI hardware investments that could affect the sustainability of current AI business models.)
- Matthew McConaughey, Michael Caine ink ElevenLabs AI voice deals (Shows how AI voice synthesis is creating new revenue streams for celebrities and transforming content creation industries.)
AI governance news
- Disrupting the first reported AI-orchestrated cyber espionage campaign (Critical example of emerging AI security threats and the need for proactive defence strategies in AI systems.)
- LLM side-channel attack could allow snoops to guess topic (Reveals new vulnerabilities in AI systems that could compromise user privacy and data security.)
- Google launches Private AI Compute for cloud Gemini with on-device-level privacy (Shows how major tech companies are addressing privacy concerns whilst maintaining cloud-based AI capabilities.)
- Google expands its security ecosystem with new Unified Security Recommended program (Indicates growing emphasis on establishing security standards for AI applications and infrastructure.)
- EU prepares to delay landmark AI rules by one year (Signals challenges in implementing comprehensive AI regulation and potential impacts on global AI governance frameworks.)
AI research news
- Grounding computer use agents on human demonstrations (Advances in making AI agents more intuitive and effective through human-guided learning approaches.)
- Project OSSAS: custom LLMs process 100 million research papers (Demonstrates how AI can accelerate scientific discovery by processing vast amounts of research literature.)
- Real-time reasoning agents in evolving environments (Breakthrough in creating AI systems that can adapt and reason in dynamic, changing conditions.)
- AI agents, productivity, and higher-order thinking: early evidence from software development (Provides empirical data on how AI tools are actually impacting developer productivity and thinking patterns.)
- Multi-agent evolve: LLM self-improve through co-evolution (Shows promising approaches for AI systems to improve themselves through collaborative learning processes.)
AI hardware news
- Microsoft launches Atlanta Fairwater AI data centre – two stories, no UPS or gen-sets (Reveals innovative approaches to data centre design that could reduce costs and environmental impact of AI infrastructure.)
- Anthropic invests $50 billion in American AI infrastructure (Massive investment signals the scale of infrastructure needed to support next-generation AI models.)
- Datacentres meet resistance over environmental concerns as AI boom spreads in Latin America (Highlights growing tensions between AI infrastructure expansion and environmental sustainability concerns.)
- Baidu teases next-gen AI training, inference accelerators (Shows Chinese advances in AI hardware that could challenge Western dominance in AI chip technology.)
- ACS, BlackRock to seal $27 billion data centre deal, report says (Demonstrates the scale of investment flowing into AI infrastructure from traditional financial institutions.)



