

This week we look at:
- A year of data on AI and agents and the impacts on knowledge work
- Alibaba’s Qwen3-Max frontier model
- xAI’s Grok 4 Fast slashing reasoning costs by 47 times
AI agents learn hard lessons
Last week we saw data from large-scale chatbot and API use; this week we’re seeing more data following around 12 months of reasoning models, widespread experimentation and the rise of tool using AI agents.
McKinsey share experiences of over 50 agentic AI builds and are seeing a consistent pattern: companies focusing on the agent itself rather than the workflow are failing. The consultancy found that experts must write thousands of desired outputs to train complex agents properly, essentially fully training them and sharing tacit knowledge. Users also complain about AI “work slop”, low-quality outputs that erode trust and make more work for others.
Google’s DORA 2025 report out this week surveyed nearly 5,000 technology professionals and echoed the question of trust: while 90% of developers now use AI tools, only 24% trust them. The research identified seven team archetypes, with only 40% seeing genuine productivity gains. Teams with strong foundations, loose coupling and fast feedback loops achieve 20-30% improvements, while those with legacy constraints see little benefit. AI acts as an amplifier, magnifying existing organisational strengths and weaknesses. The report highlights that “AI is [usually] nested in a larger system” and outcomes are shaped by overarching “sociotechnical systems” (process and culture) and not by AI’s capability alone.
Much of this data also reflects older generation models limitations. Newer reasoning models are starting to show up in the data. OpenAI’s GDPval report, evaluating AI on real economic tasks across 44 occupations, found Claude achieving just a few percent short of human experts on tasks in many fields. These frontier models handle multi-hour expert activities reasonably well (though with a 2.7% catastrophic failure rate that remains unacceptable for many professional contexts) and can increasingly work with the file formats that are integral to many working environments. The difference between GPT-4 class models that have been widely available and these newer reasoning models is substantial, and where these models failed to accelerate already capable workers, Claude and GPT-5 now can.
Examples from the GDPval tasks:

The radiology field offers a classic case study. Despite Geoffrey Hinton’s 2016 prediction that we should “stop training radiologists now”, radiologist salaries have increased 48% since 2015, with record vacancy rates. Only a minority of a radiologist’s time involves image interpretation. The rest involves patient consultation, teaching, and complex decision-making. As AI made scans faster and cheaper, consumption increased, increasing need for the human skills.
A recent blog post from Microsoft Design offers a framework for understanding these systemic complexities more deeply. They argue that thinking in workflows is “rigid, overcomplicated, and limiting” for AI systems. Instead, they propose “cybernetic” loops: continuous cycles of monitoring and coordination. This model, rooted in 1940s cybernetics theory, treats human-AI collaboration as adaptive systems responding to real-world feedback, not linear sequences.
The evidence suggests we’re at a potential inflection point. Agents leveraging tools and reasoning models are offering utility for experts and well-organised teams, but further progress could require integrating more ephemeral activity and adaptive loops rather than rigid workflows. Jobs aren’t arbitrary bundles of tasks; they’re interconnected systems of feedback and adjustment. AI systems that recognise this complexity and work within it will succeed when simple task automation hits its limits.
Takeaways: Early evidence suggests reasoning models can accelerate expert work, but only when organisations aren’t burying them in broken processes and culture. Even as models get more powerful, to unlock their potential we will still need to shift the focus from automating actions (tasks and workflows) to automating control systems (cybernetic loops). Work, especially knowledge work, is rarely linear; it is an adaptive loop of sense, interpret, decide, act, learn and repeat. AI is not a drop-in solution; it is an amplifier of the existing organisation, the networks of loops. A crucial concept from cybernetics, Ashby’s Law of Requisite Variety, states that a control system must have at least as much flexibility as the disturbances it faces. A failure to match the automation approach to the environmental “variety” explains many AI failures. And the trust we need to build in these systems will only come with adaptive governance and feedback, not merely mechanistic accuracy.
Alibaba ships a model every 36 hours
At this week’s Apsara Conference in Hangzhou, Alibaba unveiled Qwen3-Max, a trillion-parameter model that matches or beats offerings from OpenAI and Google on key benchmarks. The launch caps an extraordinary sprint from a 7 billion parameter beta model in April 2023 to frontier-scale AI in just 30 months.
Qwen3-Max scores 69.6% on coding benchmark SWE-Bench Verified and achieves perfect marks on advanced maths tests AIME25 and HMMT. The model ranks third globally on LMArena’s text leaderboard, behind only Claude Opus 4.1 and Gemini 2.5. Unlike competitors, it’s not a full reasoning model, with that coming soon.
While Western labs carefully orchestrate releases, Alibaba has launched 228 Qwen models in 2025 alone, including specialised offerings for vision, speech, and coding. CEO Eddie Wu backed this push with a multi-billion-dollar commitment over three years, exceeding Alibaba’s entire previous decade of AI spending.
Wall Street noticed, sending Alibaba shares up 10% during the conference. The recognition seems overdue. Qwen models have been downloaded 400 million times globally, spawning 140,000 derivatives.
Takeaways: Qwen has compressed a decade of expected AI development into two years through sheer focus. Their success challenges the assumption that careful, measured development beats rapid iteration. Expect Qwen to continue pushing boundaries and demonstrating to others that such progress is possible even without the budgets and heritage of the US tech giants.

Grok goes fast
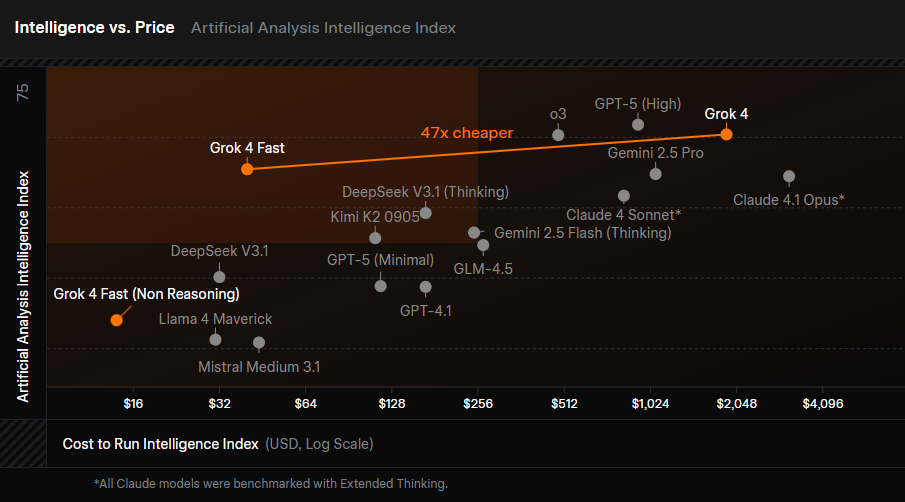
xAI launched Grok 4 Fast and here we can see it occupies new territory in the cost versus intelligence landscape. It’s 47 times lower cost than Grok 4, using 40% fewer thinking tokens whilst maintaining comparable performance. It vastly undercuts GPT-5, Claude 4 Sonnet, and Gemini 2.5 Pro. The unified architecture handles both reasoning and non-reasoning tasks in one model. If Google, Anthropic, and OpenAI can achieve similar efficiency gains with their upcoming models, AI reasoning could become more accessible than ever.
Weekly news roundup
This week’s news reveals massive infrastructure investments to support AI growth, growing concerns about data privacy and environmental impact, while businesses rush to integrate AI capabilities despite warnings of an $800 billion revenue gap.
AI business news
- ‘ChatGPT, what stocks should I buy?’ AI fuels boom in robo-advisory market (Shows how AI is democratising financial advice and transforming traditional advisory services.)
- Anthropic to triple international workforce in global AI push (Represents further rapid growth for US AI labs.)
- Databricks will bake OpenAI models into its products in $100M bet to spur enterprise adoption (Signals accelerating enterprise integration of LLMs into core business infrastructure.)
- An $800 billion revenue shortfall threatens AI future, Bain says (Critical reality check on AI economics that challenges current investment assumptions.)
- Meta in talks to use Google’s Gemini to improve ad business, the Information reports (Demonstrates how major tech rivals are collaborating to enhance AI-powered advertising effectiveness.)
AI governance news
- Neon, the no. 2 social app on the Apple App Store, pays users to record their phone calls and sells data to AI firms (Highlights concerning data collection practices for AI training that raise privacy and consent issues.)
- AI tool used to recover £500m lost to fraud, government says (Demonstrates positive use case for AI in combating financial crime and recovering public funds.)
- Deepfaked calls hit 44% of businesses in last year: Gartner (Urgent security threat that organisations need to prepare defences against.)
- The Trump administration is going after semiconductor imports (Geopolitical tensions affecting AI hardware supply chains and development capabilities.)
- Meta launches super PAC to fight AI regulation as state policies mount (Shows big tech’s organised resistance to AI governance efforts.)
AI research news
- Federation of agents: a semantics-aware communication fabric for large-scale agentic AI (Advances multi-agent systems architecture for better coordination and scalability.)
- Analyzing uncertainty of LLM-as-a-judge: interval evaluations with conformal prediction (Improves reliability of using LLMs for evaluation tasks through better uncertainty quantification.)
- Hierarchical retrieval: the geometry and a pretrain-finetune recipe (Enhances information retrieval methods crucial for RAG systems and knowledge bases.)
- RPG: a repository planning graph for unified and scalable codebase generation (Enables automated code generation at repository scale, advancing AI-assisted development.)
- Baseer: a vision-language model for Arabic document-to-markdown OCR (Expands AI capabilities to underserved languages and document processing tasks.)
AI hardware news
- Nvidia to invest up to $100 billion in OpenAI, linking two artificial intelligence titans (Massive infrastructure commitment showing the scale of investment needed for next-generation AI.)
- OpenAI Stargate announces five new datacenter sites in US (Physical infrastructure expansion critical for supporting growing AI compute demands.)
- CoreWeave expands OpenAI deals to as much as $22.4 billion (Shows the scale of cloud infrastructure partnerships needed to support AI development.)
- UK’s Nscale raises $1.1 billion in AI data center frenzy (European investment in AI infrastructure to compete with US dominance.)
- Most coal-fired power plants will delay retirement to feed AI boom, energy secretary says (Reveals concerning environmental impact of AI’s massive energy requirements.)



