



Data centre dollars prop up the US economy
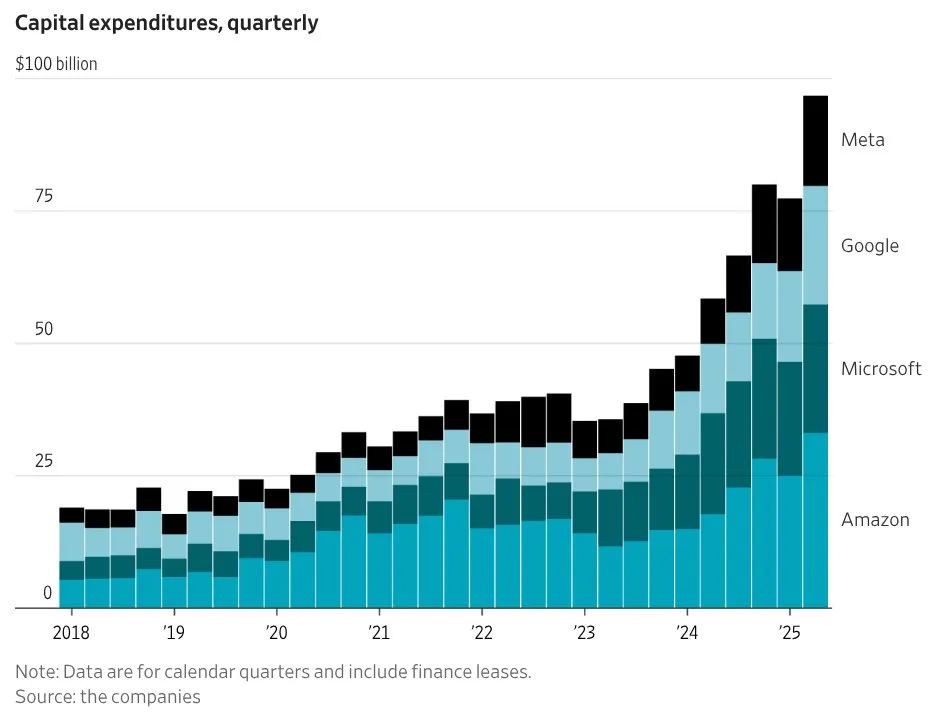
This chart provides a clear picture of the staggering scale of data centre AI infrastructure investment, that is now contributing more to US economic growth than consumer spending!
What started as quarterly burn of around $15 billion in 2018 has exploded to nearly $100 billion in 2025. Amazon leads with a $100 billion annual commitment, whilst Microsoft and Google each plan $75-80 billion. According to recent analysis, AI capital expenditure may already represent 2% of US GDP, potentially adding 0.7% to growth in 2025.
This isn’t just another tech bubble, it’s acting as a massive private sector stimulus programme. Without this infrastructure boom, the US might have faced a 2.1% GDP contraction in Q1. We’re witnessing spending on a scale that approaches railroad infrastructure investment in the 19th century as a percentage of GDP. But unlike railways that lasted a century, these datacentres house rapidly depreciating technology. GPUs become obsolete in years, not decades. Meanwhile, this capital reallocation is starving other sectors. Venture capitalists are funding almost exclusively AI projects. Traditional infrastructure projects are struggling for investment. Cloud companies are laying off staff whilst pouring billions into GPU clusters.
Takeaways: We’re living through a historic moment where private companies are essentially running an infrastructure programme that’s keeping the US economy afloat. The concentration of compute power in a handful of companies echoes the railroad monopolies of the Gilded Age. Whether this spending proves justified or becomes the most expensive bet in corporate history will define the next decade of technological and economic development.
Weekly news roundup
This week saw major funding rounds and infrastructure investments signal the AI industry’s continued expansion, whilst regulatory frameworks and security concerns highlight the growing need for responsible AI deployment across sectors.
AI business news
- OpenAI raises another funding deal, from Dragoneer, Blackstone and more (Shows continued investor confidence in leading AI companies and the massive capital requirements for developing frontier models.)
- Google rolls out Gemini Deep Think AI, a reasoning model that tests multiple ideas in parallel (Demonstrates the shift towards more sophisticated reasoning capabilities in AI models, crucial for complex problem-solving applications.)
- Tim Cook says Apple is ‘very open’ to AI acquisitions (Signals Apple’s strategy to accelerate AI development through acquisitions rather than solely internal R&D.)
- Amazon to pay New York Times at least $20 million a year in AI deal (Illustrates the emerging business model for media companies licensing content to AI developers.)
- ChatGPT’s study mode is here. It won’t fix education’s AI problems (Highlights the challenges of integrating AI tools into education whilst maintaining academic integrity.)
AI governance news
- Trump may not replace Biden-era AI rule (Suggests potential continuity in US AI policy regardless of political changes, important for long-term planning.)
- Meta faces Italian competition investigation over WhatsApp AI chatbot (Shows how European regulators are scrutinising AI integration in dominant platforms for antitrust concerns.)
- Voice actors push back as AI threatens dubbing industry (Illustrates the ongoing tension between AI capabilities and creative industry employment.)
- Enterprises neglect AI security – and attackers have noticed (Warns of the security vulnerabilities emerging as companies rush to deploy AI without proper safeguards.)
- EU law for GenAI comes into force this week (Marks a major milestone in AI regulation that will affect global AI development and deployment strategies.)
AI research news
- AlphaGo moment for model architecture discovery (Suggests breakthrough in automated AI architecture design, potentially accelerating model improvement.)
- Persona vectors: monitoring and controlling character traits in language models (Advances understanding of how to control AI behaviour, crucial for safe and reliable AI systems.)
- AlphaEarth Foundations helps map our planet in unprecedented detail (Demonstrates AI’s potential for environmental monitoring and climate change research.)
- Where to show demos in your prompt: a positional bias of in-context learning (Provides practical insights for optimising prompt engineering strategies.)
- A survey of self-evolving agents: on path to artificial super intelligence (Explores the frontier research area of AI systems that can improve themselves autonomously.)
AI hardware news
- OpenAI to launch AI data centre in Norway, its first in Europe (Shows geographic expansion of AI infrastructure and considerations for data sovereignty.)
- Nvidia says its chips have no ‘backdoors’ after China flags H20 security concerns (Highlights geopolitical tensions affecting the AI hardware supply chain.)
- SK Hynix surpasses Samsung as top memory maker for first time (Reflects the impact of AI demand on memory chip markets and supply chain dynamics.)
- Tesla signs $16.5B chip manufacturing contract with Samsung (Shows the massive scale of custom chip investments for AI and autonomous vehicles.)
- Meta to spend up to $72B on AI infrastructure in 2025 as compute arms race escalates (Demonstrates the unprecedented capital requirements for competing in frontier AI development.)



