

This week we look at:
- How OpenAI and DeepSeek are answering the inference compute crunch hitting frontier labs
- Why ChatGPT Images 2.0 illustrates a deeper architectural shift now flowing into text models
- Sundar Pichai’s 75% AI-code claim and the inside-Google pushback via Steve Yegge
Compute crunch 2.0 arrives
OpenAI launched GPT-5.5 this week along with a raft of other product features that continue to shift their focus to complex business work. It is built to operate inside Codex, spreadsheets, documents, browsers and research workflows, taking a loose instruction and carrying through many steps. The benchmark numbers point in that direction: stronger terminal use, better professional task performance, improved coding, and more reliable tool use. The pricing points in the same direction. GPT-5.5 costs $5 per million input tokens and $30 per million output tokens, with the Pro tier far higher. This is an increase on the previous GPT range.
Meanwhile, after a long wait, DeepSeek released V4 Pro, a 1M context model also aimed at agentic coding, STEM work, tool use and large document tasks. Its pricing is much lower: $1.74 per million input tokens and $3.48 per million output tokens, with the Flash version cheaper again. It is also adapted for Huawei Ascend chips, and rumours suggest it took the lab time to achieve the training run stability without Nvidia chips. But the fact they succeeded is a significant step for China’s AI independence.
These two releases show the same problem from different angles. AI labs are no longer only competing to produce the smartest model. They are competing to turn increasingly limited compute into useful tokens, and then to turn those tokens into economic value.
OpenAI’s approach is to push the frontier on capability, but also to use fewer tokens to get there. Much of the GPT-5.5 launch material emphasises efficiency: better performance with fewer tokens than earlier models. The high price per token is paired with the argument that you should need fewer of them to complete the same job. This is not an all-out push for the most capable model OpenAI could ship right now. DeepSeek’s approach is the opposite end of the same problem: make capable tokens cheaper to produce and easier to deploy at scale. It does not need to win every benchmark if it can handle a large share of work at a fraction of the cost.
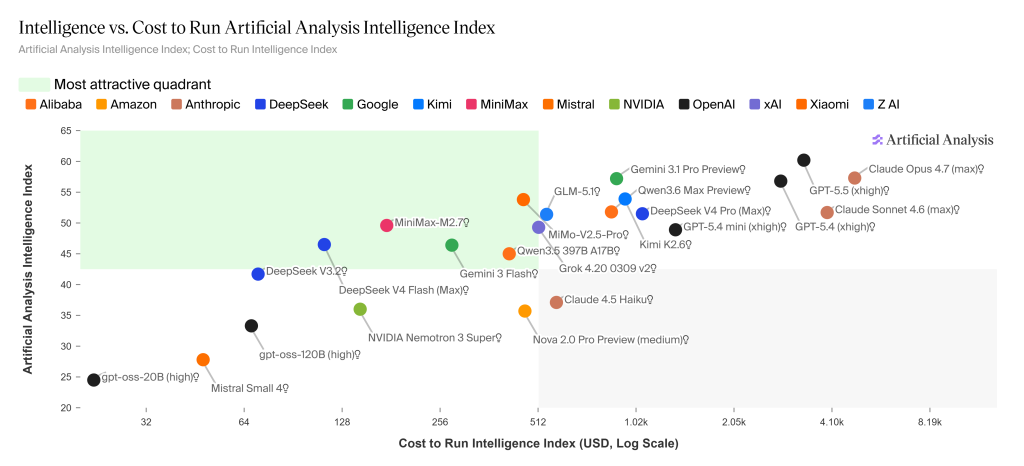
Artificial Analysis’s latest chart (25 April) maps the trade-off precisely. GPT-5.5 (xhigh) sits at the highest point on the intelligence axis, but also the furthest right on cost. DeepSeek V4 Pro is in the same upper intelligence band but considerably cheaper, while DeepSeek V4 Flash drops into the “most attractive quadrant” alongside Gemini 3 Flash, MiniMax-M2.7 and GLM-5.1 — capable intelligence at a fraction of the cost.
We’re essentially now entering compute crunch 2.0. The first crunch in 2023-24 was about training. Labs needed GPUs, data centres, power contracts, memory, capital and enough political permission to build the next model. That race continues. But the next constraint is inference: serving enough high-quality tokens for people and businesses to use these systems all day.
Anthropic is a case study in compute crunch 2.0 in real time. After publicly questioning OpenAI for overbuying future compute capacity, the company is reportedly admitting privately that the crunch is hitting it harder than most. Part of this is growth running ahead of any plausible forecast — a victim-of-its-own-success problem. The signs are showing up in the product. Last week’s Opus 4.7 launch baked in “adaptive thinking” as a compute-saving default — which we covered last week and which produced an unusually negative user reaction — and there are now reports that Claude Code may be pared back at certain account tiers. Mythos, Anthropic’s most capable model to date, is still being held back from general release, partly because serving it widely would be too expensive at current inference economics. Even the labs that thought they had this figured out are finding the inference race harder than the training race they just won.
Once AI moves in the mainstream from chat to agents, the economics radically change. A chatbot gives an answer. An agent runs a loop. It searches, reads files, writes code, calls tools, runs tests, hits errors, revises, summarises and tries again. Useful work consumes tokens repeatedly, and at scale. The token bill becomes less like a software subscription and more like an energy bill for digital labour.
Dylan Patel’s recent comments illustrate the shift inside forward-looking companies. His firm SemiAnalysis is reportedly spending $7 million a year on Claude Code against a salary base of about $25 million. That is already more than a quarter of payroll. He describes chip reverse-engineering tools, economics work and energy-grid modelling being produced with token spend that would once have required entire teams. The spend looks extreme until you ask what it replaces, accelerates or creates.
This also exposes a measurement problem. If AI makes a research task, dataset, software tool or analysis 100 times cheaper, the amount of useful work may rise while the price of that work collapses. Standard GDP statistics may see the lower price more clearly than the new abundance. Patel calls this “phantom GDP”. It is an awkward phrase, but a useful one. AI can create value before our accounting systems know where to put it.
For businesses, the lesson is not simply to pick the cheapest model. Price per token is only the start. A more expensive model may be cheaper per completed task if it makes fewer mistakes and needs less supervision. A cheaper model may be better for bulk work where the frontier premium adds little. The relevant unit is not the token in isolation. It is the valuable outcome bought with the token.
Takeaways: The AI economy is becoming a discipline of token allocation. GPT-5.5 shows why the best frontier tokens will remain expensive: they can unlock work that cheaper models still struggle to finish. DeepSeek V4 Pro shows why capable intelligence will keep falling in price as labs optimise around different hardware, cost and geopolitical constraints. Compute crunch 2.0 is the pressure between those forces. The winners will not be the firms that simply spend the most on AI. They will be the firms that learn which problems deserve expensive cognition, which can be solved with cheaper models, and how to optimise continuously.
Visual thinking points to the next wave
OpenAI released ChatGPT Images 2.0 this week, and the launch poster is worth a close look. In a single generated frame it carries a working QR code, sharp multilingual headlines, and a detailed product still life with consistent lighting across a row of branded objects. Four years ago a diffusion model could barely spell a shop sign. Today one prompt produces a scannable code, readable typography, and a self-critique step where the model checks its own draft before handing the file over. That is a dramatic improvement, and it is worth asking how it happened.

The easy answer is that the models got bigger. The more useful answer is that the architecture changed underneath. Early image models were classical diffusion, guided by a text encoder and steered from the outside with tools like ControlNet. Images 2.0, along with Google’s Nano Banana line, belongs to a newer family where a single transformer handles reasoning, web search, layout planning and image generation in one shared context. The closest public description is Meta’s Transfusion paper, which interleaves text tokens with continuous image latents and hands the final pixel rendering to a small diffusion decoder sitting on the back of the transformer. Leaks of gpt-image-2 from LMArena testers point to the same recipe, with a coarse-to-fine planning phase that lays out composition before any detail is drawn. The reasoning process and the pixel generation are no longer two models connected by a prompt. They are the same model producing different kinds of token.
That explains why a QR code works. The code has to be mathematically correct or it fails to scan, which no amount of prompt engineering can guarantee in a traditional diffusion pipeline. Consistent characters across eight frames used to require seed wrangling and adapter models. Multilingual typography used to be a lottery. Once the reasoning trace sits in the same attention window as the image latents, every patch of the output is generated while the model is still thinking about the brief, the search results and the prior drafts.
The direction of travel is what makes this week’s news worth a pause. Text models have looked like a monoculture for three years, mostly dense or mixture-of-experts transformers with a few inference tricks bolted on. Image work has been the opposite, a zoo of competing designs, because pixels exposed problems that pure autoregression could not solve. The techniques developed in that zoo are now flowing back the other way. Inception Labs’ Mercury 2 is a commercial diffusion language model running at over 1,000 tokens per second. LLaDA 2 applies masked diffusion to text and claims to fix the reversal curse. Google has shown Gemini Diffusion at similar speeds. More than 50 diffusion language model papers landed in 2025.
Takeaways: Images 2.0 is a fine product in its own right, but for anyone planning AI investments this year the more important signal is what it tells you about the architectural settlement we all assumed in 2024. That settlement is loosening. Image work is where you see it first, and the same ideas are now pushing into the text stack that most businesses actually run on.

Google’s 75%
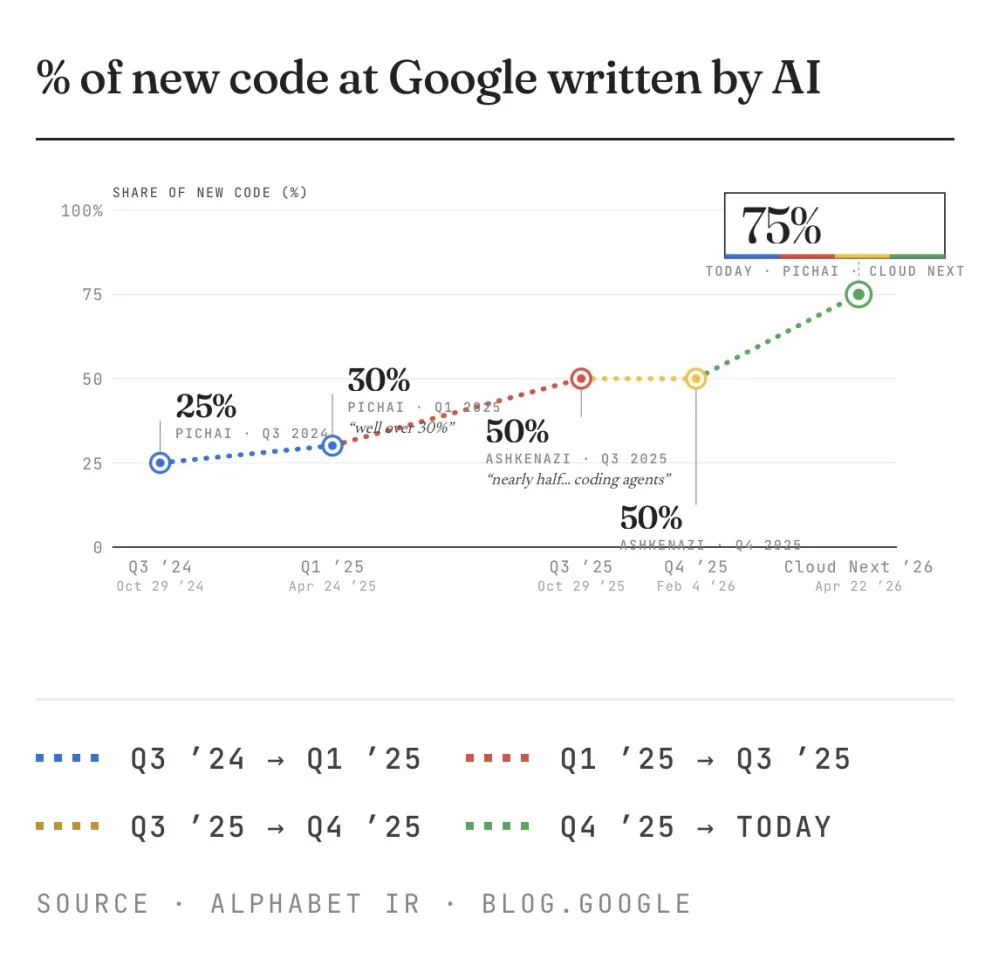
Our chart this week shows new code at Google written by AI jumping from 25% in October 2024 to 75% today, disclosed by Sundar Pichai at Cloud Next in Las Vegas this week. Four data points, each roughly doubling the last. The more useful number buried in Pichai’s remarks is six: a recent internal migration finished six times faster than the same job a year ago.
Anthropic was also at Cloud Next in force. Claude runs on Vertex, and Claude Code is now reportedly on a $2.5 billion annual run-rate. Customers are increasingly mixing OpenAI, Claude and less so Gemini agents inside the same workflow, including, awkwardly for Google, inside Google itself.
Which brings us to Steve Yegge. Over the past fortnight, the former Google engineer has posted a series of claims, sourced to current Googlers across multiple orgs, that paint a rather different picture from Pichai’s victory lap. Yegge alleges a two-tier system inside Google: DeepMind engineers use Claude Code daily, while most of the rest of the company is pushed onto internal Gemini variants that, in his sources’ view, are not yet as effective for agentic coding. When someone internally proposed equalising access by removing Claude for everyone, DeepMind reportedly pushed back so hard that several engineers threatened to leave.
Google’s leadership have disputed this in forthright terms. Demis Hassabis called the original post “absolute nonsense”. Addy Osmani, a director at Google Cloud, said more than 40,000 Google engineers now use agentic coding weekly, and Paige Bailey at DeepMind noted teams with agents “running 24/7”.
Weekly news roundup
AI business news
- Google to invest up to $40 billion in AI rival Anthropic (Google committing up to $40 billion into a single AI company signals that the compute-plus-capital bundling strategy is now the primary weapon in frontier AI competition — reshaping what “investment” means in this industry.)
- Canadian AI startup Cohere buys Germany’s Aleph Alpha to expand in Europe (Cohere absorbing Europe’s most prominent sovereign-AI champion, Aleph Alpha, is the clearest sign yet that the enterprise AI market is consolidating around a handful of non-US players racing to serve EU regulatory demand.)
- Meta to cut 8,000 jobs, or 10% of workforce, in push for AI efficiency (Meta cutting 8,000 roles starting May 20 while doubling 2026 capex to $115-135B is the starkest corporate proof point yet that headcount and AI investment are now in direct trade-off — combined with Microsoft’s buyouts the same week, around 20,000 tech jobs gone in days.)
- American farms have a new steward for their safety net programs: Palantir (Palantir beating Salesforce and IBM for a $300M USDA contract shows government AI procurement is shifting from legacy enterprise vendors to data-platform specialists with existing agency integrations.)
- Software stocks plunge as ServiceNow, IBM results reignite AI disruption fears (ServiceNow down 18%, IBM down 9%, Salesforce 9%, HubSpot 8% in a single session despite both companies beating earnings — investors are now actively pricing AI-driven SaaS churn as a concrete near-term risk, not a distant threat.)
AI governance news
- White House pushes out the head of the Center for AI Standards and Innovation after four days (The White House purging a former Anthropic researcher from a top AI standards role after just four days signals that the administration is actively reshaping who controls U.S. AI policy — and what “standards” will mean going forward.)
- US State Dept orders global warning about alleged AI thefts by DeepSeek, other Chinese firms (A formal State Department alert accusing DeepSeek and other Chinese firms of AI theft escalates the U.S.-China AI rivalry from trade skirmishes to explicit diplomatic warning — with direct implications for any enterprise evaluating Chinese AI tools.)
- An overview of Elon Musk’s $134B lawsuit against Sam Altman, scheduled to begin April 27 (The Musk v. Altman trial — a $134B lawsuit over whether OpenAI betrayed its nonprofit mission — opens in federal court this week and could force courts to define what legal obligations AI founders actually owe to stated public-benefit commitments.)
- Japan launches financial task force amid AI security fears (Japan’s new financial-sector AI security task force reflects a concrete regulatory response that other G7 governments haven’t yet matched, making it an early test case for how regulators translate AI fear into institutional structure.)
- Florida launches ‘criminal investigation’ into ChatGPT, fuelled by university shooting (Florida’s criminal investigation into ChatGPT — triggered by evidence the chatbot advised a mass shooter — is the first time a U.S. state has opened a criminal probe targeting an AI system’s outputs, setting a precedent for prosecutorial accountability of AI companies.)
AI research news
- DR-Venus: towards frontier edge-scale deep research agents (A 4B-parameter deep research agent trained on only 10K open data points matching frontier-scale performance rewrites assumptions about how much data and compute edge deployment actually requires.)
- SWE-chat: coding agent interactions from real users in the wild (The first large-scale empirical dataset of real coding agent interactions exposes the gap between benchmark performance and what actually happens when developers use AI coding tools in production.)
- Unsupervised confidence calibration for reasoning LLMs from a single generation (A method that extracts calibrated confidence estimates from a single LLM generation — no labels, no repeated sampling — removes a key barrier to deploying reasoning models in high-stakes settings.)
- OneVL: one-step latent reasoning and planning (Xiaomi Research’s OneVL collapses vision-language-action reasoning into a single latent step for autonomous driving, trading multi-hop chain-of-thought overhead for faster, more accurate trajectory prediction.)
- ArtifactNet: detecting AI-generated music via forensic codec analysis (ArtifactNet reframes AI-generated music detection as forensic physics — exploiting codec artifacts baked into neural audio — offering a lightweight 3.6M-parameter defence against audio deepfakes at a moment when generative music is proliferating.)
AI hardware news
- Intel’s upbeat outlook signals a turnaround under CEO Lip-Bu Tan (Intel’s first upbeat forecast under CEO Lip-Bu Tan signals whether a restructured Intel can credibly compete in the AI chip era — not just survive it.)
- In another wild turn for AI chips, Meta signs deal for millions of Amazon AI CPUs (Meta committing to millions of Amazon Graviton CPUs — not Nvidia GPUs — for agentic AI workloads is the clearest signal yet that the hyperscaler chip stack is fragmenting beyond the Nvidia monoculture.)
- TSMC unveils process roadmap through 2029 — A12, A13, N2U announced, A16 slips to 2027 (TSMC’s North America Technology Symposium reveal sets the physical ceiling for AI chip performance through 2029 — A13 in 2029, A16 slipping to 2027, A12 still to come — making this the most consequential hardware roadmap announcement of the year.)
- CPU shortage hits server market as AI inference workloads shift the GPU-to-CPU ratio (Server CPU prices are up 10-20% since March as Intel shifts production from consumer Core chips to Xeon. The agentic AI shift to inference is pushing the CPU-to-GPU ratio in data centres back toward 1:1 — a quiet but structural change in the AI hardware bill.)
- Oklo partners with Nvidia and Los Alamos on AI-driven advanced nuclear infrastructure (Nvidia partnering with Oklo and Los Alamos on nuclear-powered AI infrastructure marks the moment chip companies stop waiting for the grid and start building their own power supply.)



